
Atlas - Mainframe Processes
Leading design on high-impact functionality

Information Architecture | UI Design | UX Design
January - April 2021
What is Atlas?
Atlas is an internal developer tool that allows software engineering teams to automate the build and deployment process for their existing applications / software. It is composed of the user interface, and a configuration file where developers can make changes to their build/deployment pipeline.
Atlas is also built on top of existing DevOps tools/services.
Background & Challenge
50-60% of this organization's applications run on legacy mainframe computers. In order to modernize the company, they are bringing in 20% of applications to Atlas in order to follow DevOps practices.
Solution
The solution was to build out separate workflows (onboarding, deployment, backouts) into Atlas for mainframe projects
What I learned
Onboarding - hypotheses was that users would need to add additional source types / libraries to their program, but this was something they rarely did, and must be done manually in GitHub
Deployments - users were not familiar with the concept of GitHub repos and branches
Backout Process - users navigated through multi-select dropdowns better than a list
What I did
Removed a step within the onboarding flow that asked users to add additional source types
In addition to in-context tooltips, ensure there is enough documentation and training in place
Used a version with a multi-select dropdown instead of a list for users to select multiple items
Final Output
Onboarding Flow
Deployment Flow
Backout Flow
Full Design Process
Discovery & Initial Research
There was a lot of ambiguity going into building mainframe processes. Pretty much everything was unknown in terms of how mainframe applications worked, and how they could work with Atlas. I first through some initial discovery calls with 5 different developers (mainframe and DevOps experts) to understand how mainframe works today, what are existing pain-points, and what mainframe developers cared about.
The main thing about mainframe applications is that they consist of component versions that are "consolidated" into one bigger group, and then put into a snapshot deployed.
This is different from a cloud application, where an application is put into an artifact is deployed.
Biggest challenges
Components can be used across different projects, making it difficult to find the right one
It's challenging to keep track of builds and what has changed in them
Backing out a deployment is difficult, because you can select a specific part to build out
Design Goals
The goal for mainframe processes was to build a more efficient method for mainframe developers to build and deploy their applications. I started by thinking about some "how might we..." questions
How might we help developers bring mainframe applications into Atlas?
How can we show all components and their contents so users can select the right ones to deploy?
How can we build a robust process to help users only rollback part of a deployment?
How can we design a way for developers to see previous builds, deployments and what has changed?
While speaking to multiple developers and DevOps engineers, there was no consensus on how things should move forward. Based on this, we started with quick iterative loops (almost daily meetings!), I slowly uncovered unknowns while co-designing with the team.
Phase 1 — Onboarding Flow
Background
Onboarding already exists for cloud applications on Atlas, however there were two new design challenges when it came for onboarding for Atlas.
RACF validation - identification (ID and password) used to access resources for mainframe. Most teams would not have this set up beforehand, so this must be added in.
Source types - this dictates the type of code and data stored in each program (stored in GitHub). Libraries are created for each source type but they may not have been created on build.
I designed out various user flows with the engineers, before landing on one to be designed and tested.
Source Types
Source types are important because libraries need to be created for each source type. Libraries store specific information that is necessary for the build process.
There was a hypothesis that users will want to have libraries created for source types that don't exist yet. The design challenge became a way to visually display existing source types and help users add new ones. Usually applications would have around 15, but there are edge cases where applications could have up to 200.
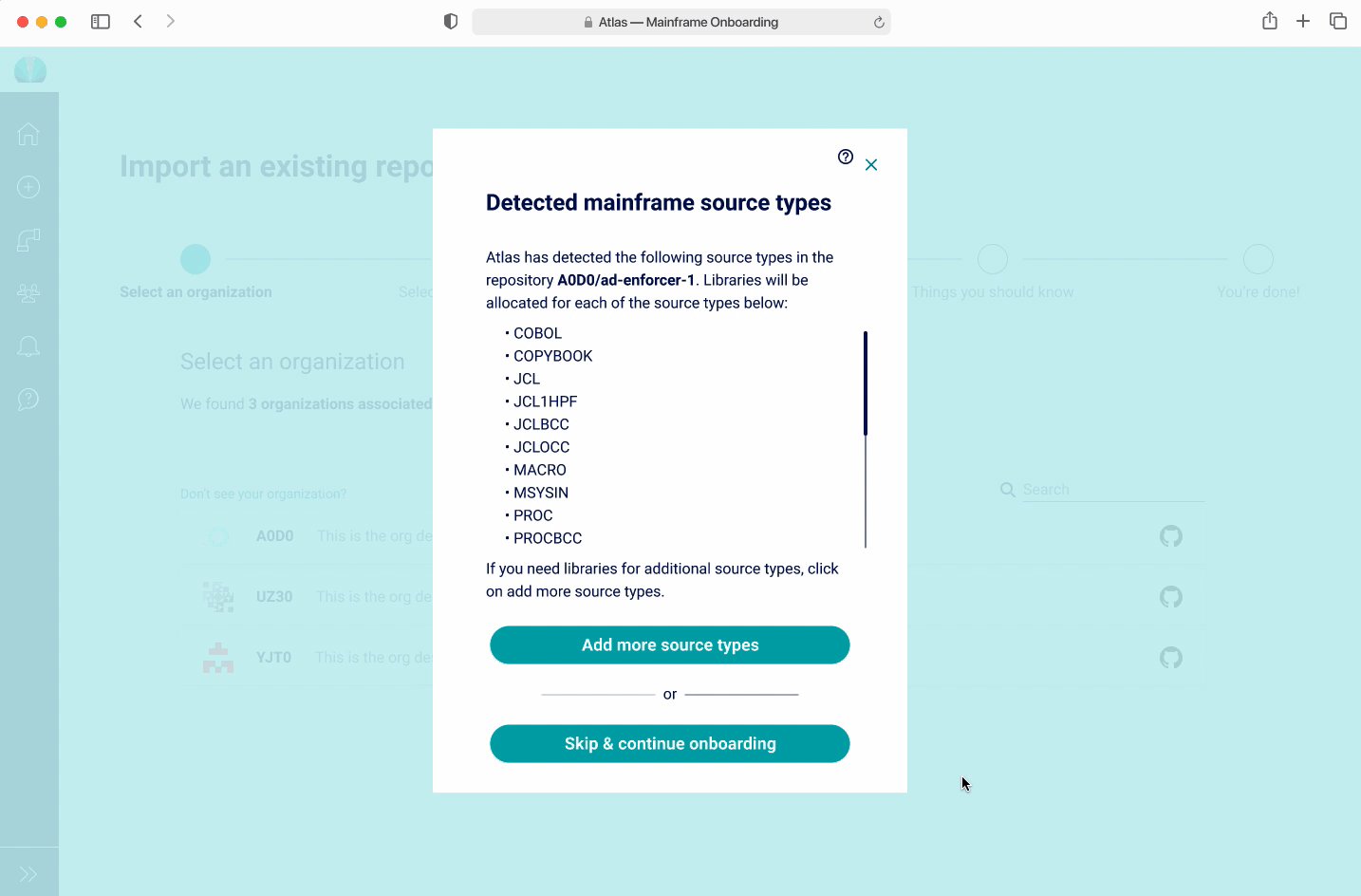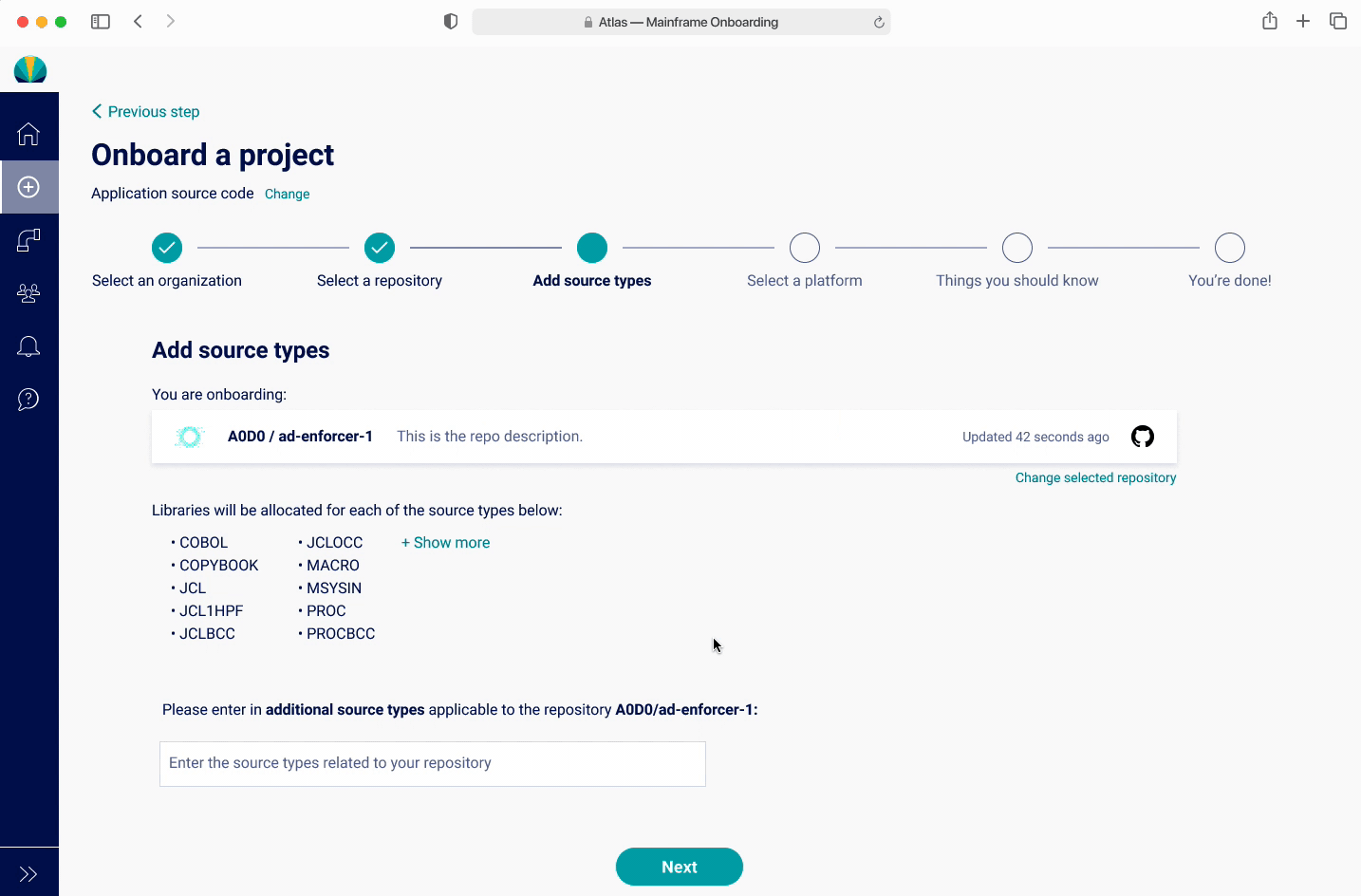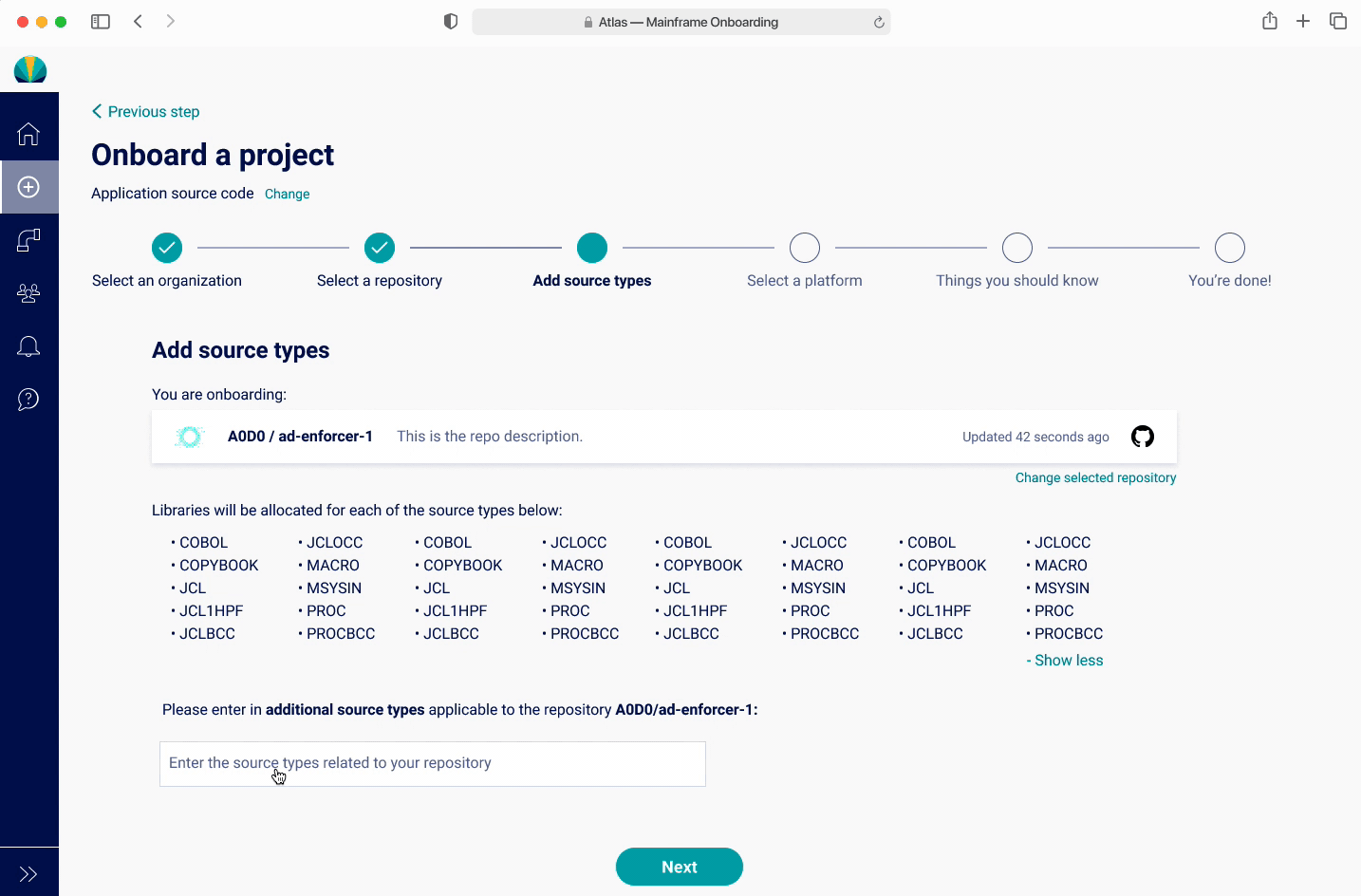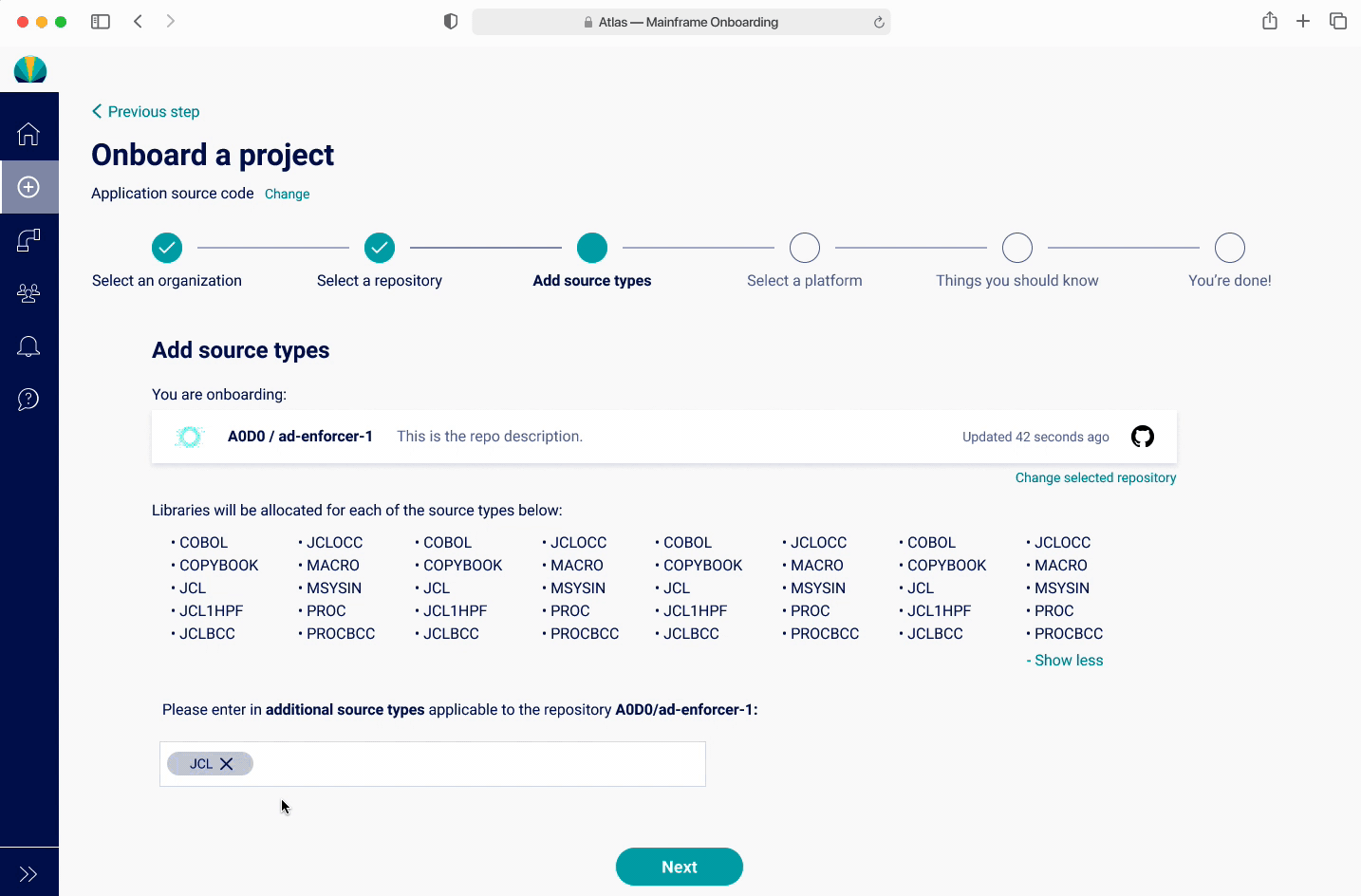
Onboarding - Adding Source Types V1
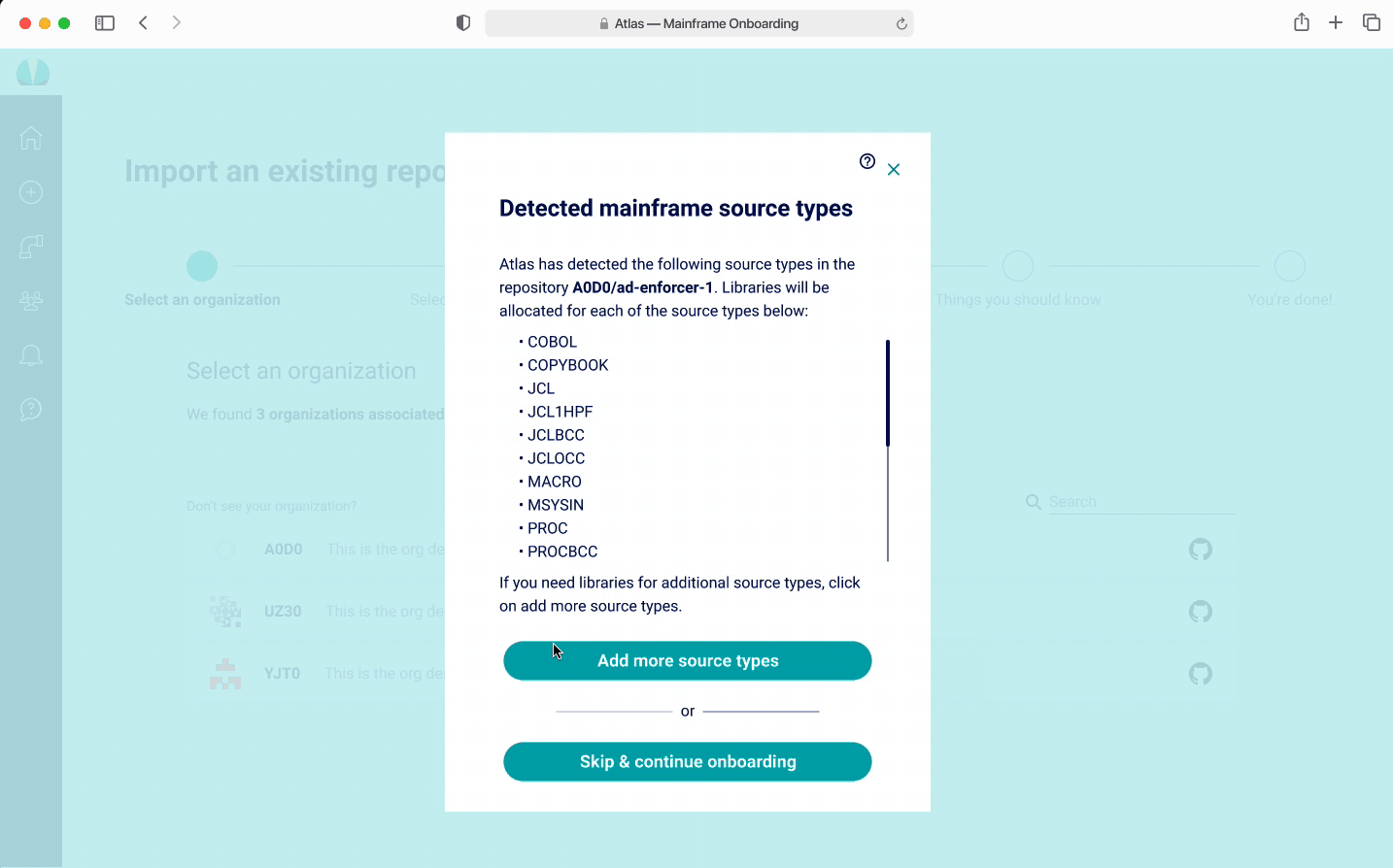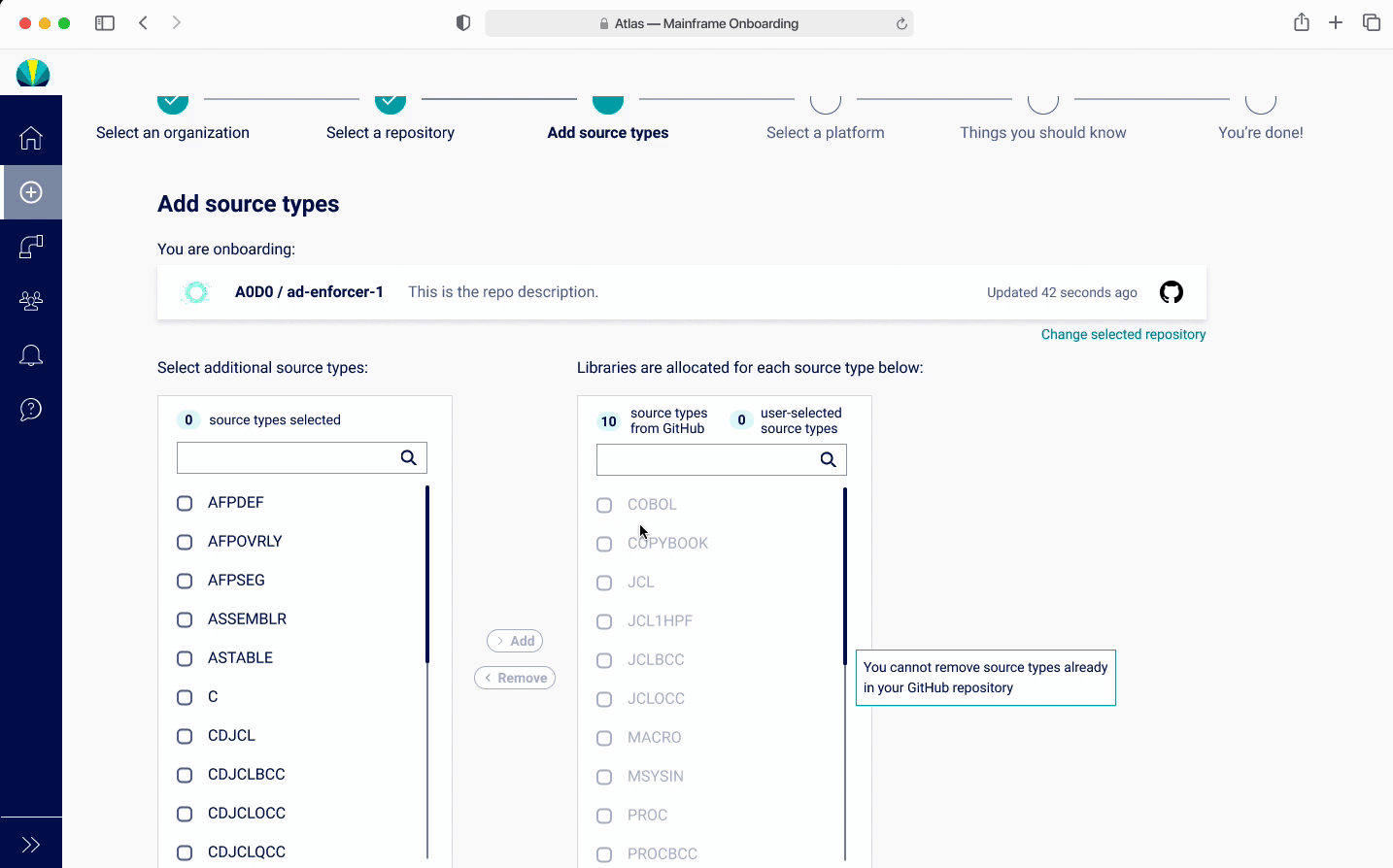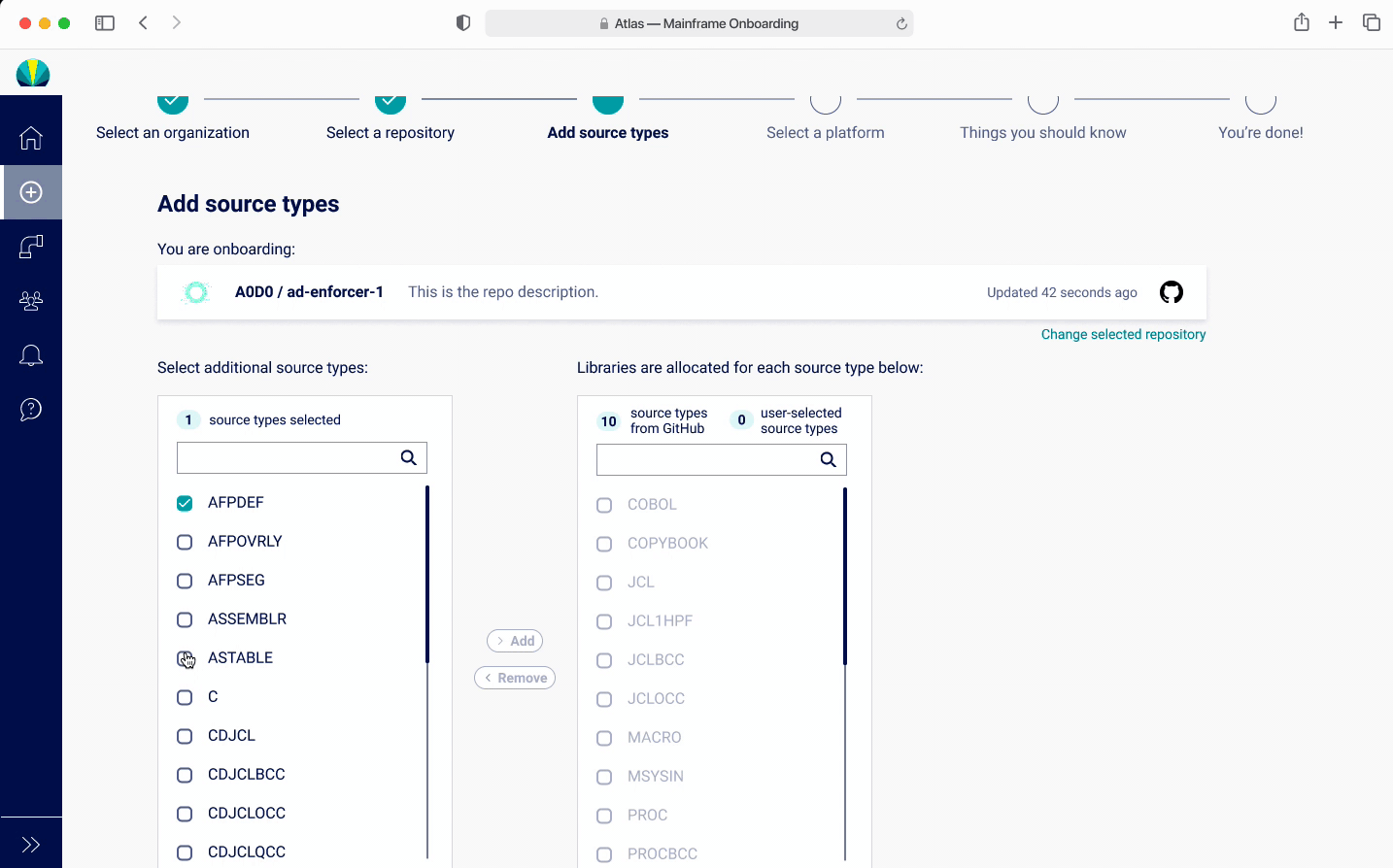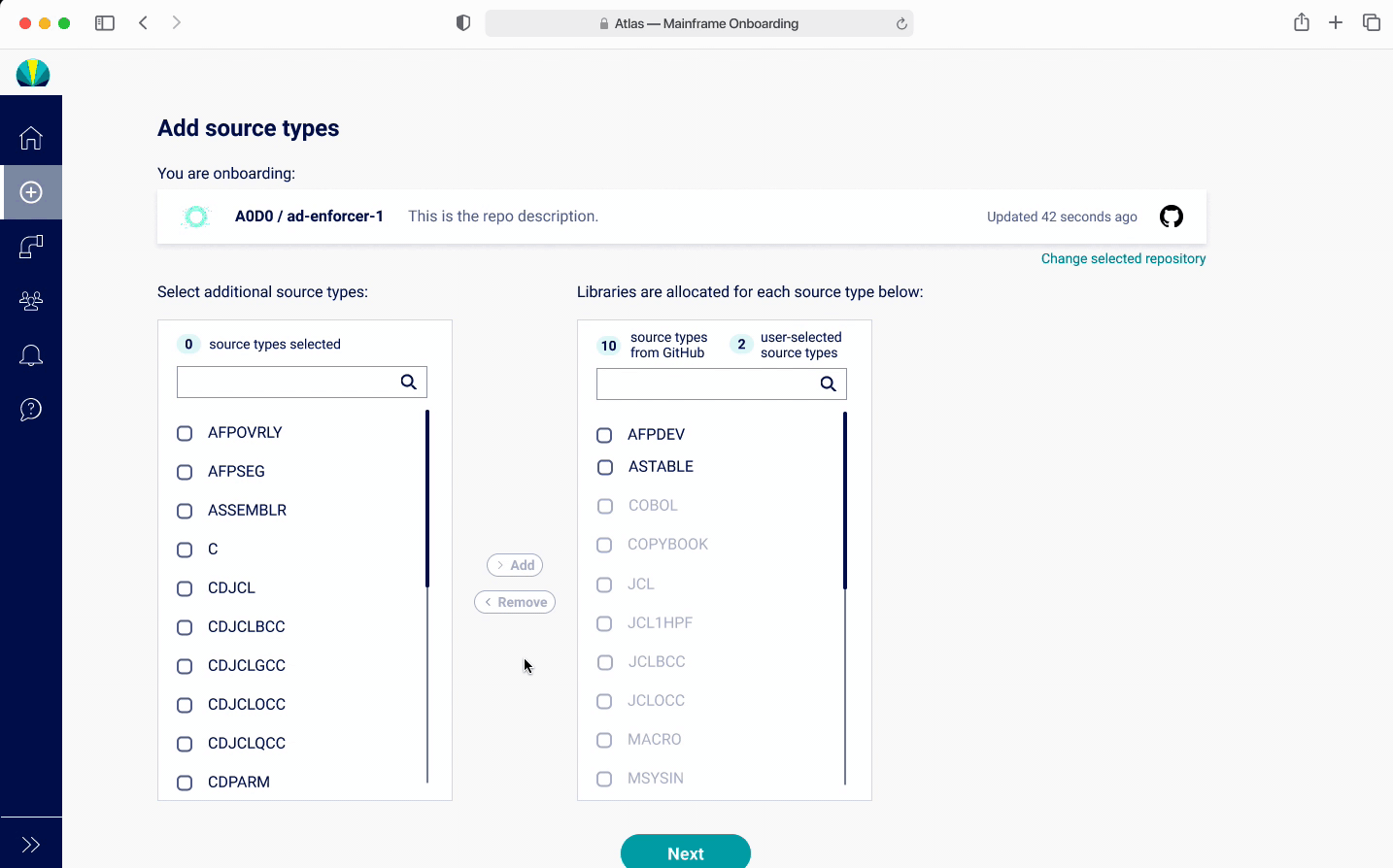
Onboarding - Adding Source Types V2

Onboarding - Adding Source Types V3
Validation & Testing Goals
I did some quick testing and gather feedback with 3 users. I wanted to talk to SMEs to determine if the source type creation made sense at this step of the flow, and if so, which version of the prototype users had the least amount of errors with
Findings
Users rarely needed to add a source type
Users would create a new GitHub folder when they add a new source type (this is mandatory)
Users would usually choose the same members across environments in a source typex
Iterations
I did a quick iteration after discovering the findings, with keeping the popup showing the source types, with a CTA for users to be able to refresh this list and add new source types. However users found this to be quite confusing since they would need to go to GitHub and refresh. Also, since they rarely needed to add a source type, found this unnecessary.
Onboarding - Adding Source Types V4
Since users rarely needed to add source types, I took out the step completely, and had the onboarding go straight to the confirmation page that shows the existing source types. If users really wanted to, they can go into GitHub, and re-onboard their project.
Onboarding - Adding Source Types Final
Onboarding - Final Flow
Phase 2 - Deployment Flow
Background
There originally was no streamlined way to deploy multiple projects or components at once. A developer would manually coordinate and send multiple items to an approver, who would have to perform multiple steps. This was a big problem for mainframe applications, since they consist of multiple components versions that would need to be consolidated and deployed as one package.
A deployment request ended up being the solution as a way to streamline the approval / deployment process for developers and 'approvers'.
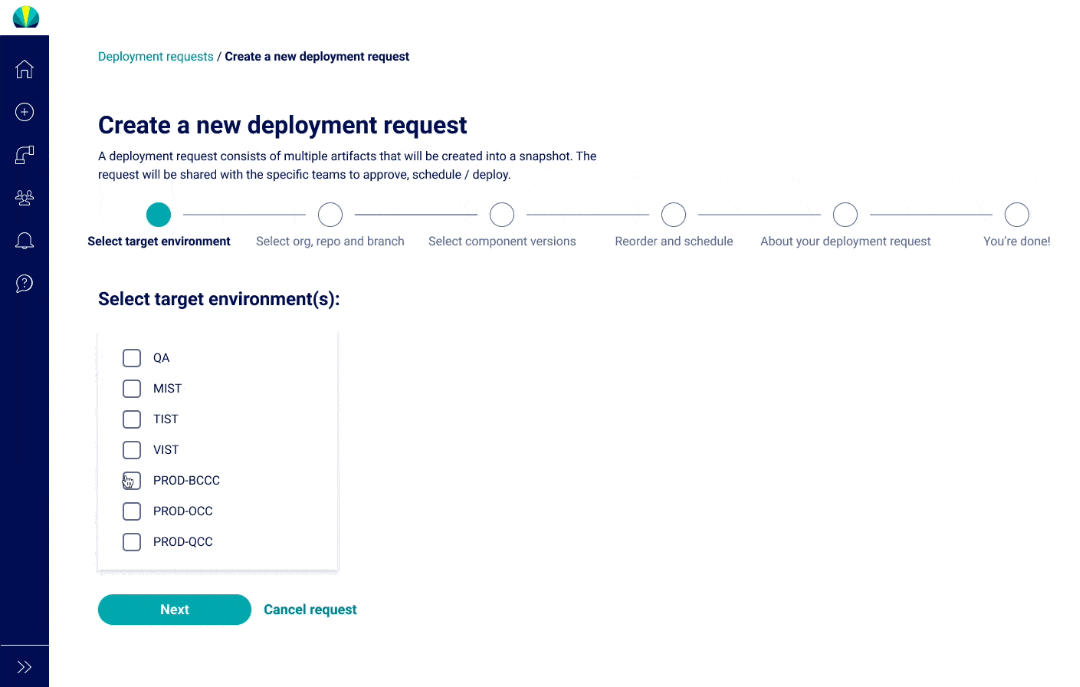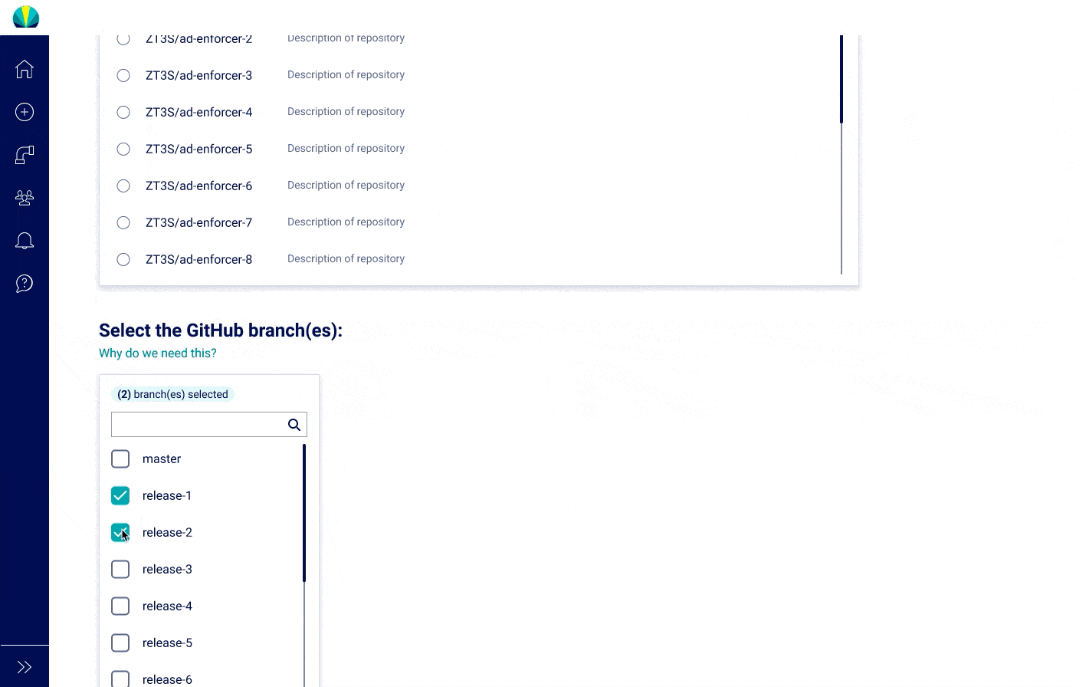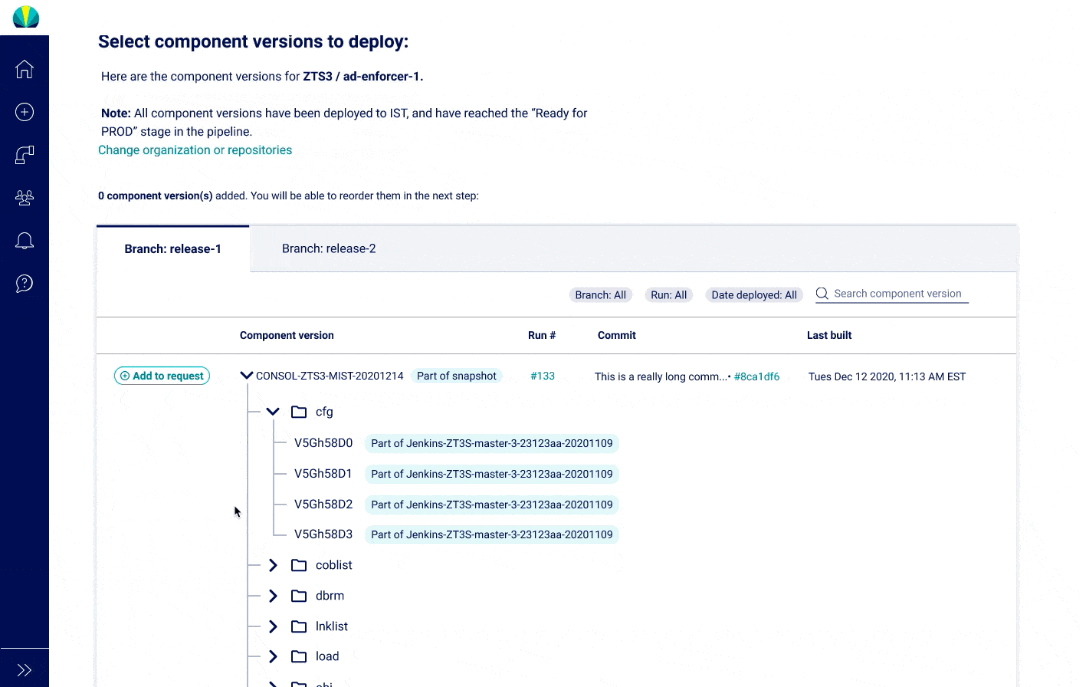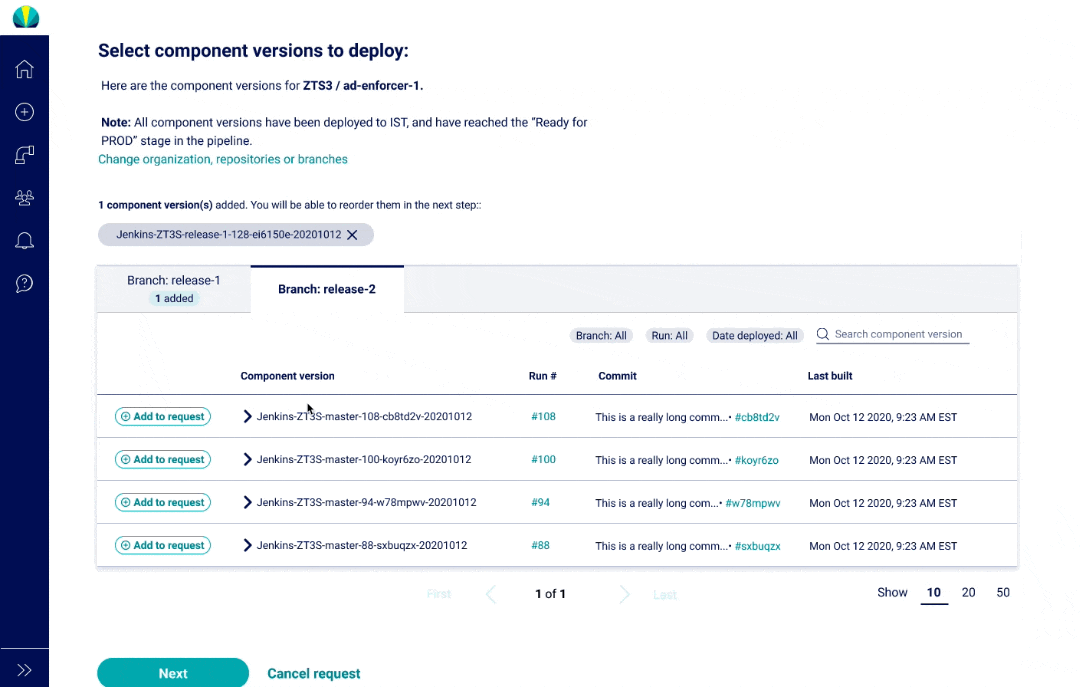
Deployment requests were designed in parallel for mainframe and normal cloud applications, and one of the biggest design challenges was designing the steps to be flexible but show consistency.
Mainframe vs. Distributed Deployments
Through quick iterations (almost on a daily basis!) with SMEs and mainframe developers, I designed out the additional steps required for mainframe deployments piece-by-piece.
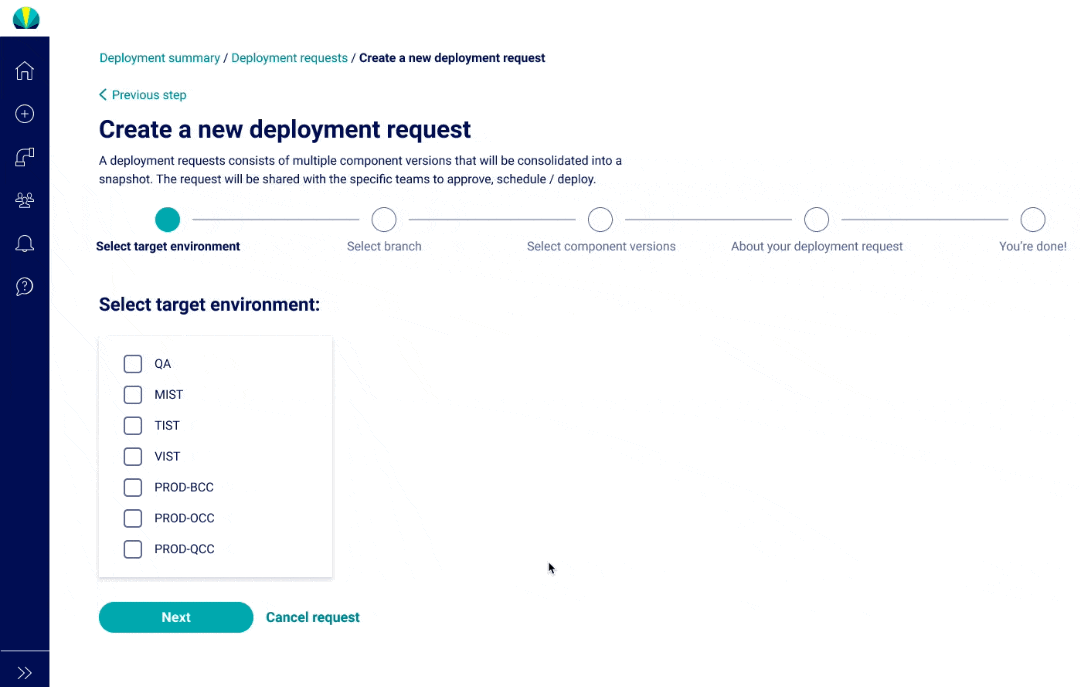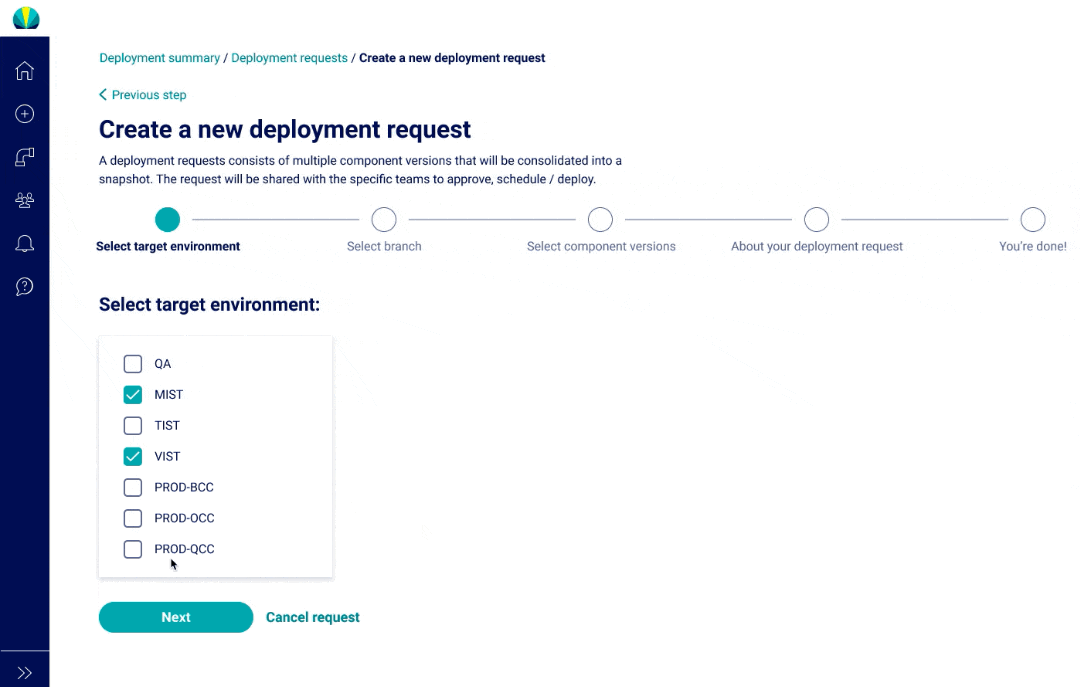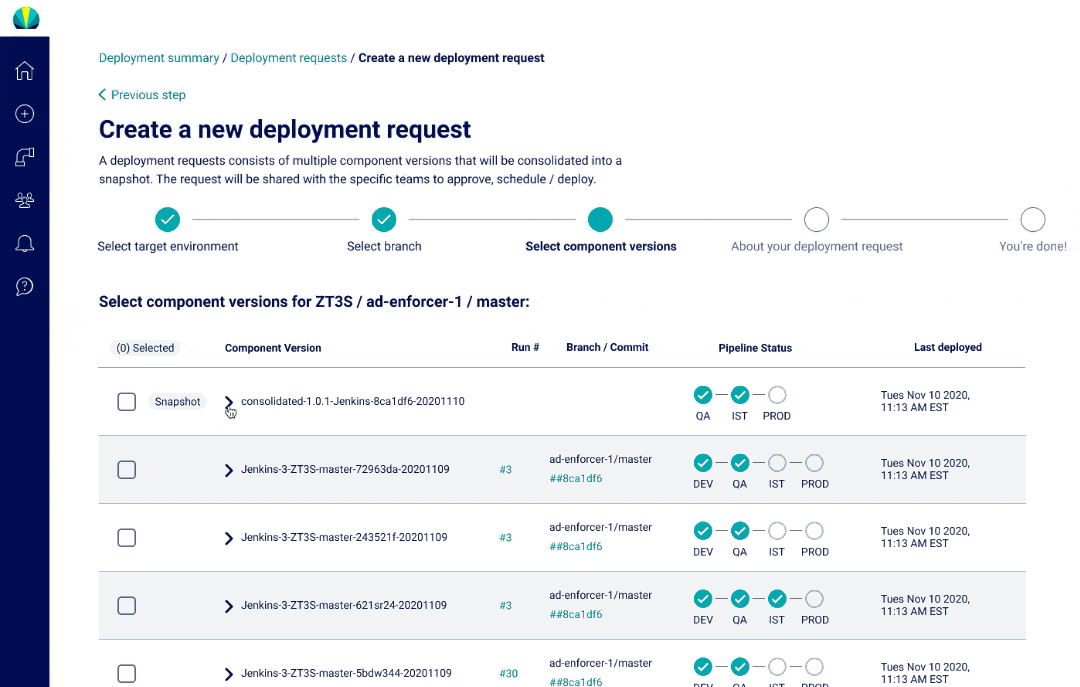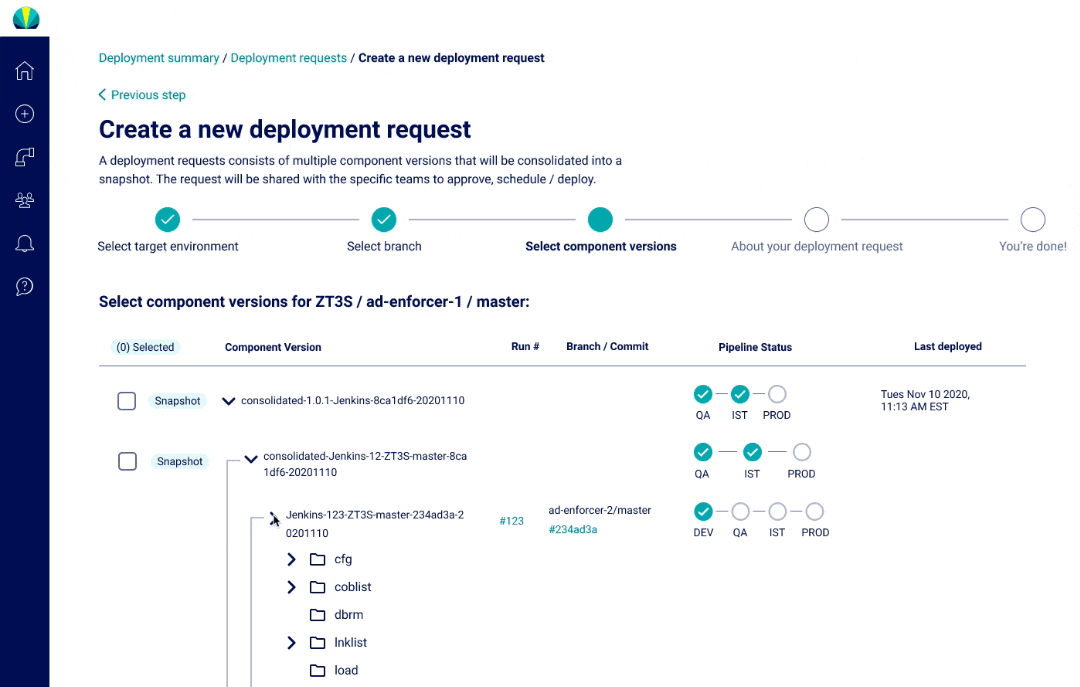
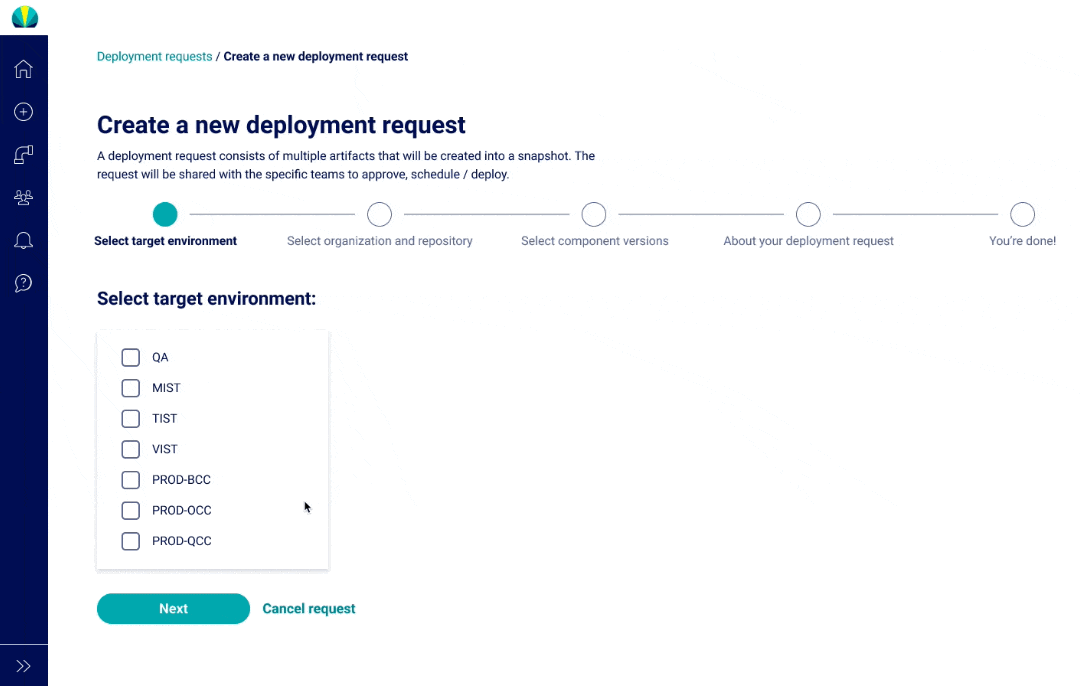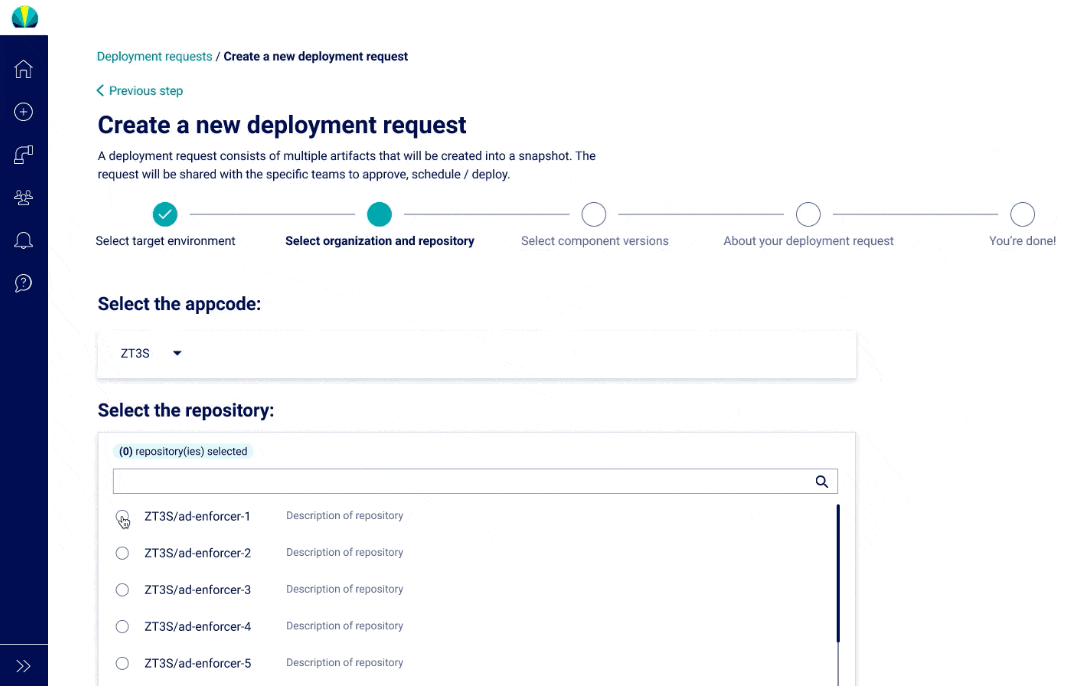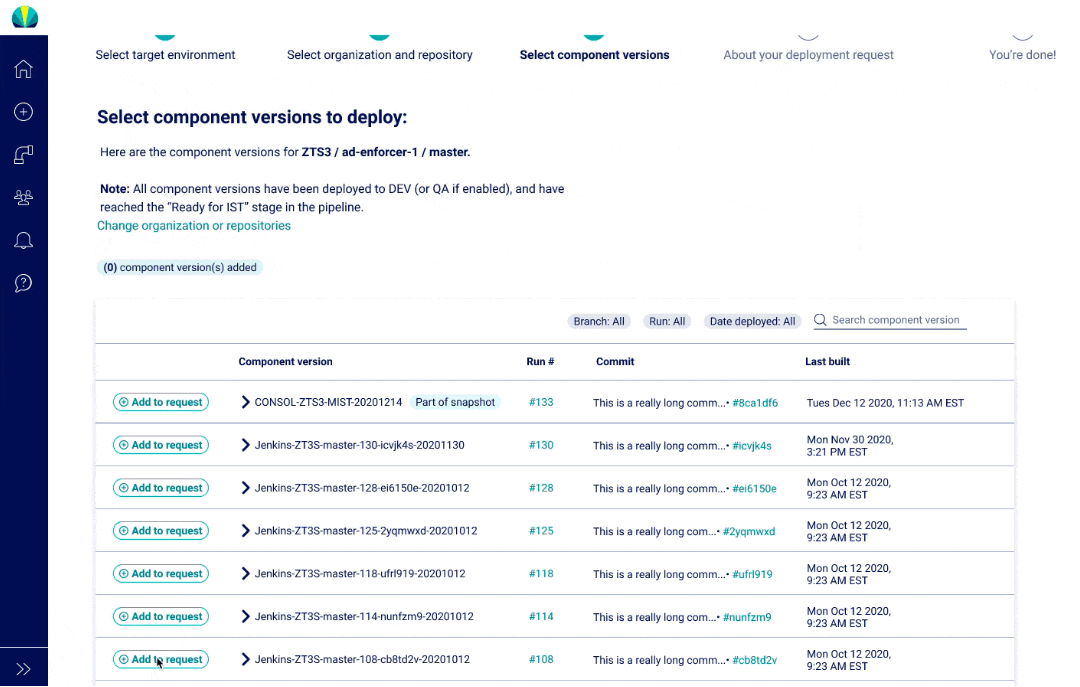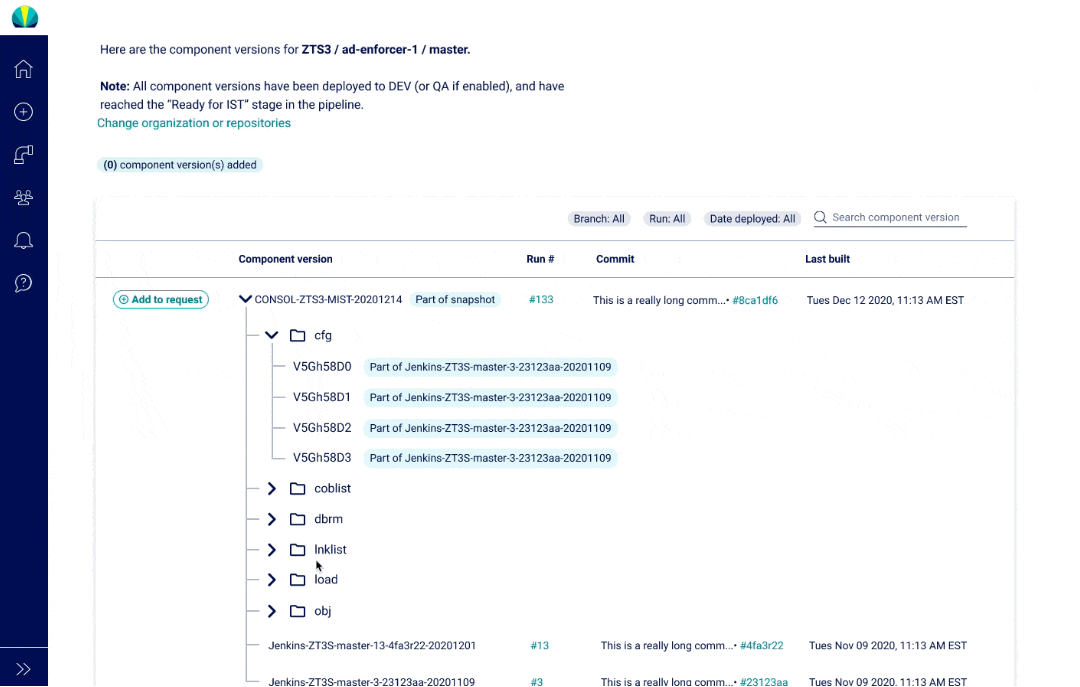
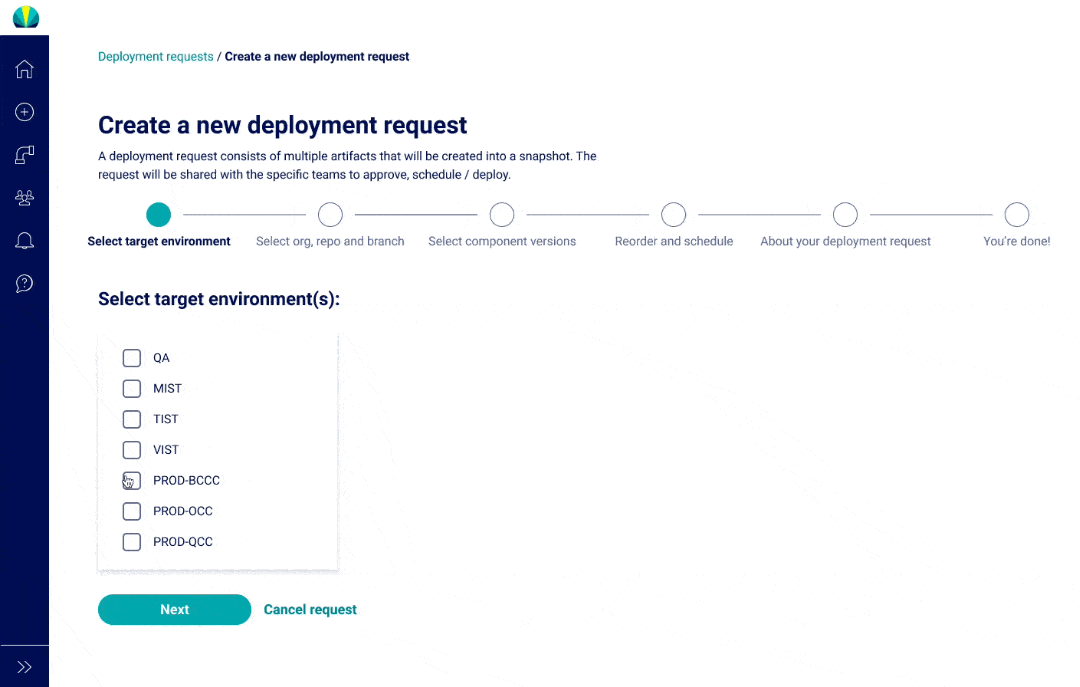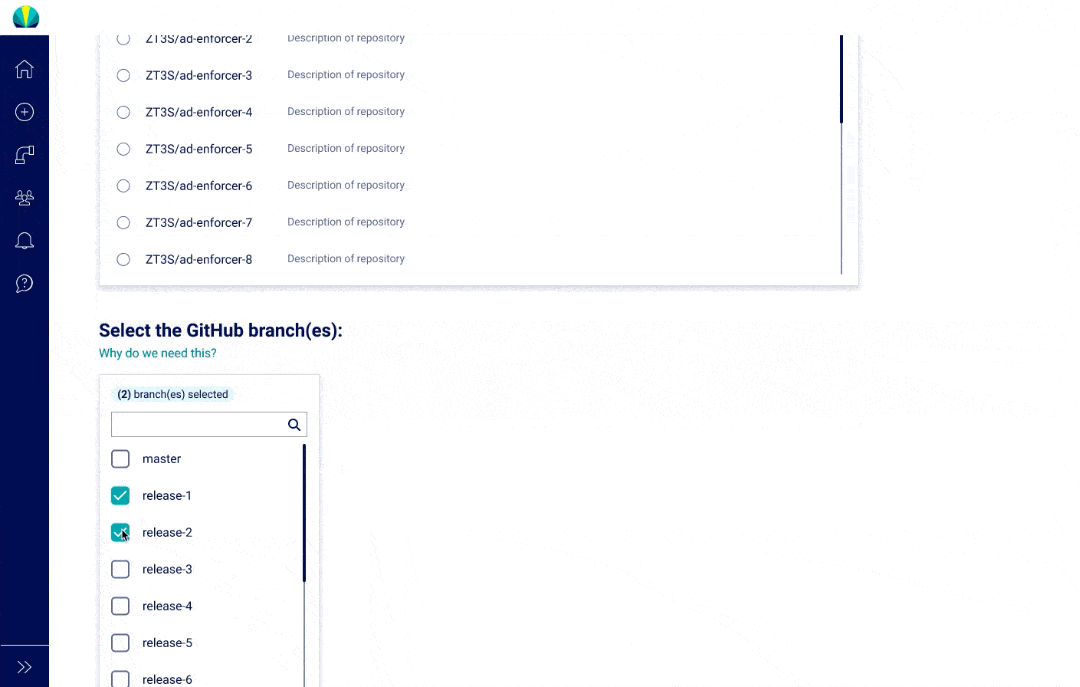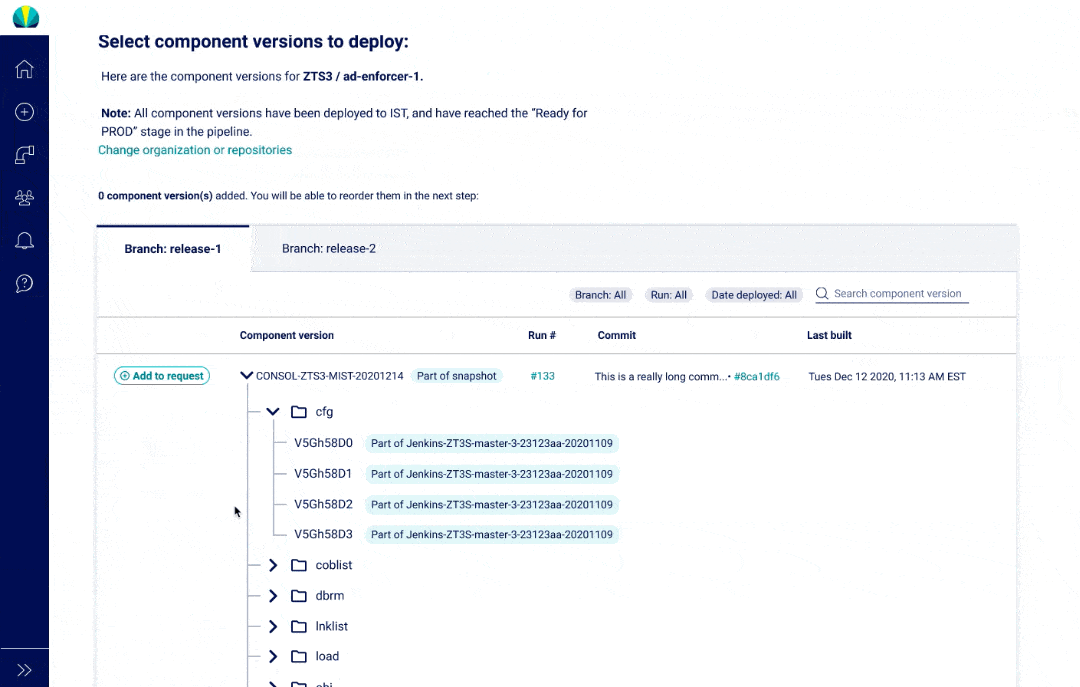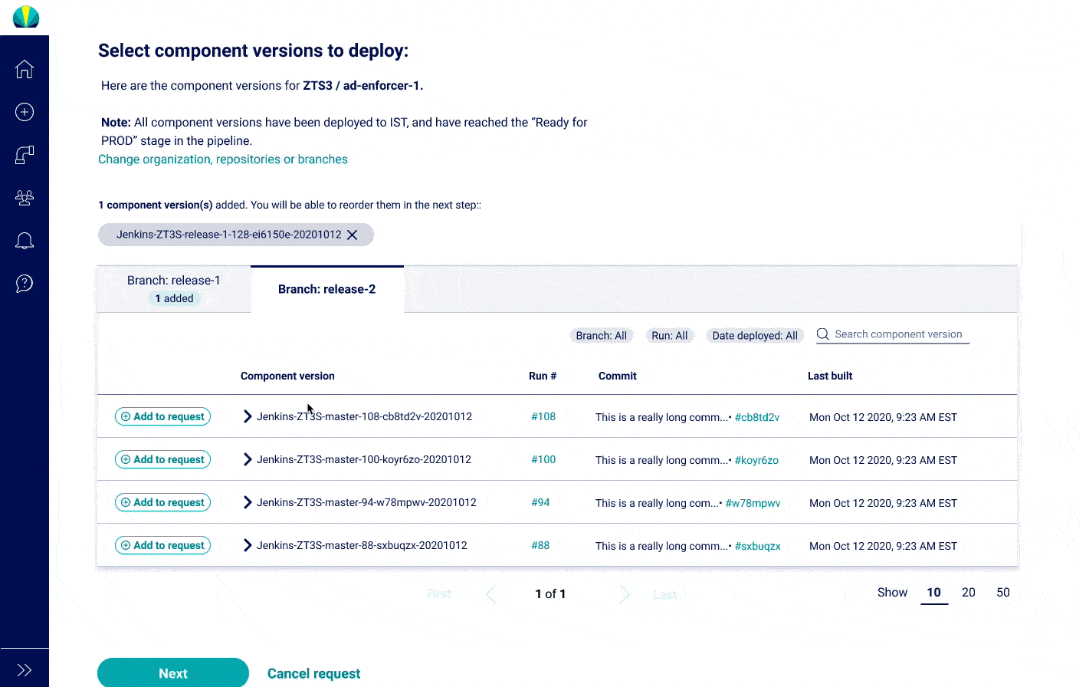
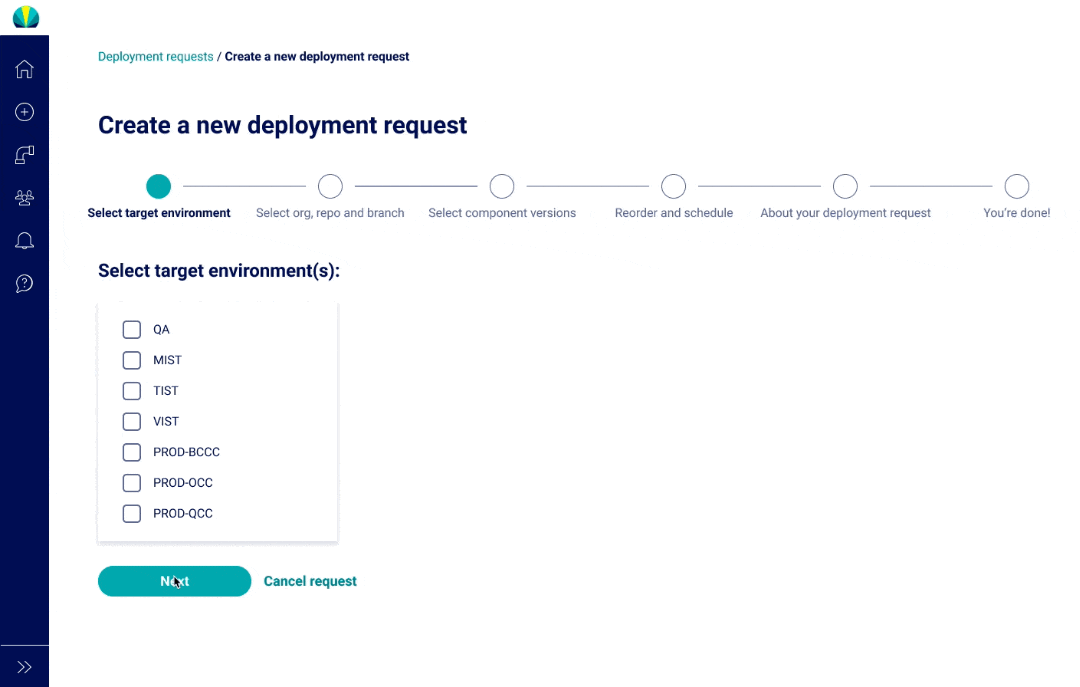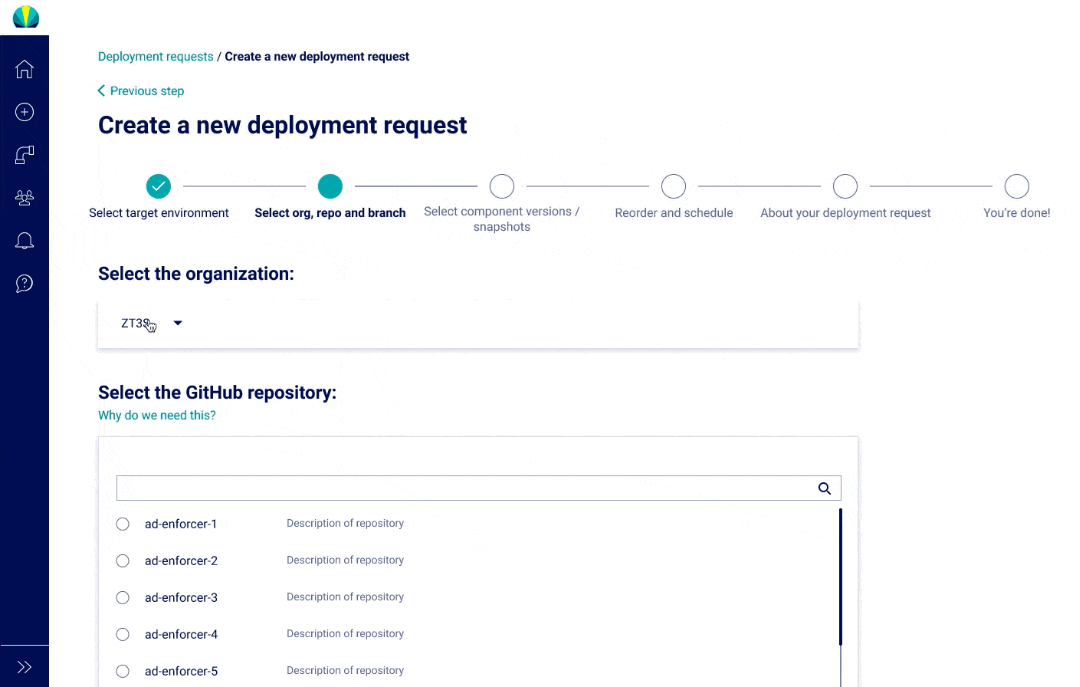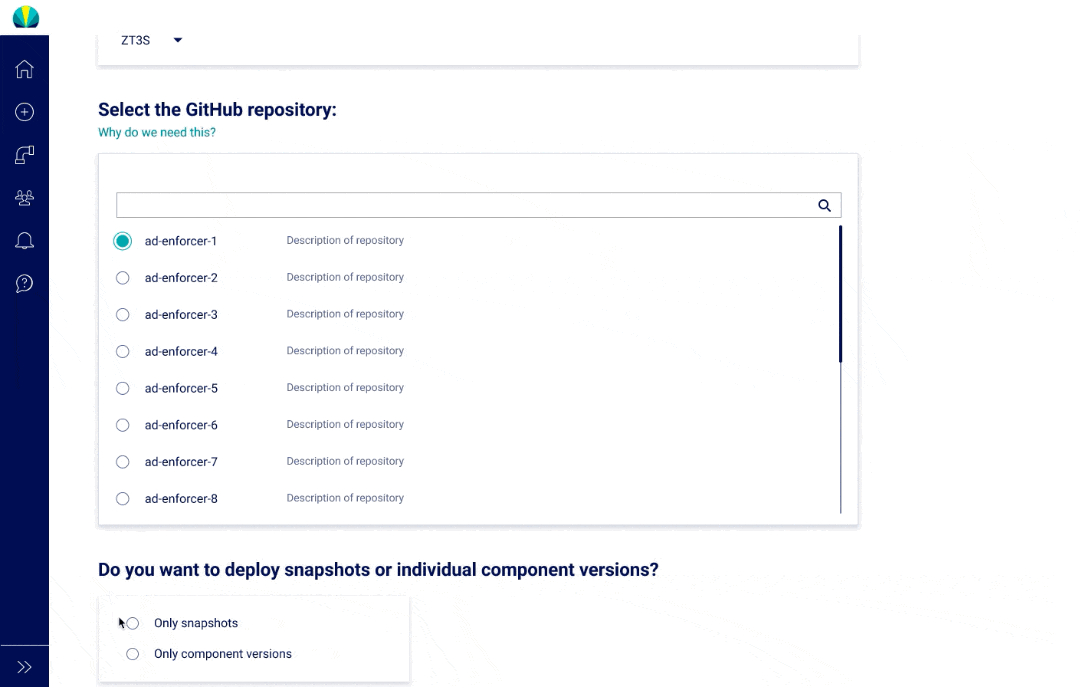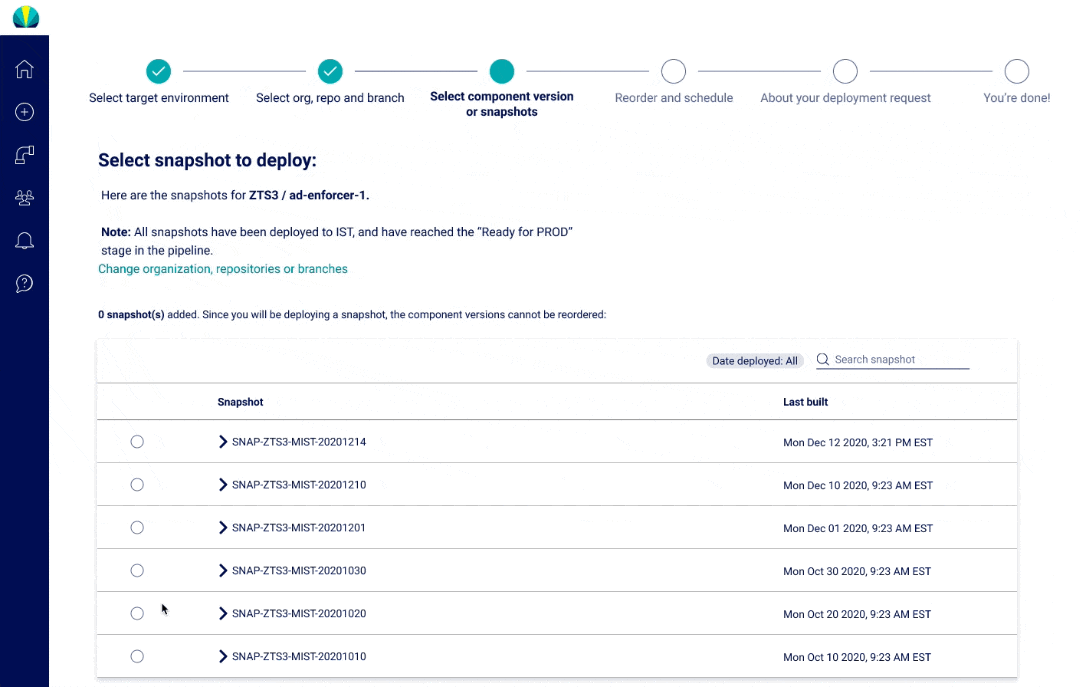
User Testing Findings
Deployment request testing was recently done for distributed applications, but did another round of testing specific for mainframe applications. The main challenge I found from users was that all of them did not understand why selecting repositories or branches was necessary since it wasn't a concept that was familiar in mainframe applications.
Although the tooltips helped explain why Helios required this information, I understood it would take a while before the users would become familiar with the new processes, and this risk was brought up to the product owners. More documentation and training would be necessary when rolling out this feature.
Phase 3 — Backouts Flow
Background
Mainframe processes consists of tons of components, and new versions of these components are created all the time. Users would want to just rollback one specific component out of a program, since if they rebuild the whole program, the versions may be out of sync.
Backing out is a new flow that does not exist in Atlas, and similarly to deployment requests, 'Backout Requests' were built as a way to streamline the process for multiple parties.
Backouts Flow
End-to-end Design
Designing high-fidelity mocks of the flow consisted of multiple steps that were very similar to existing onboarding or deployment flows.
Quick iterations were created to come up with the final flow.
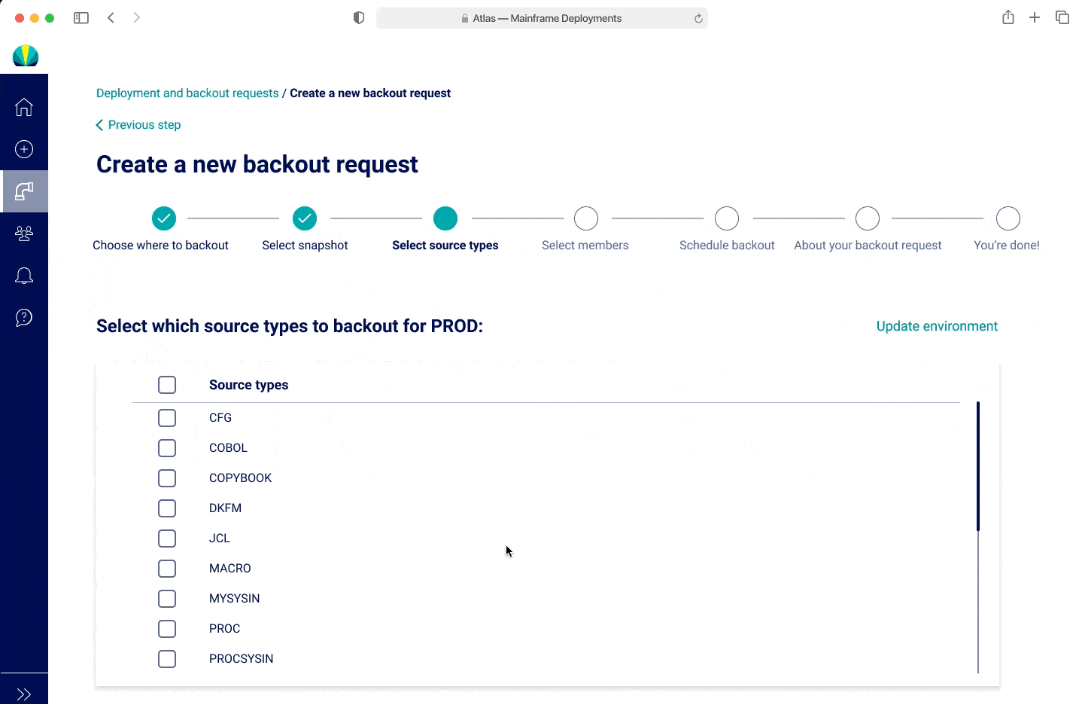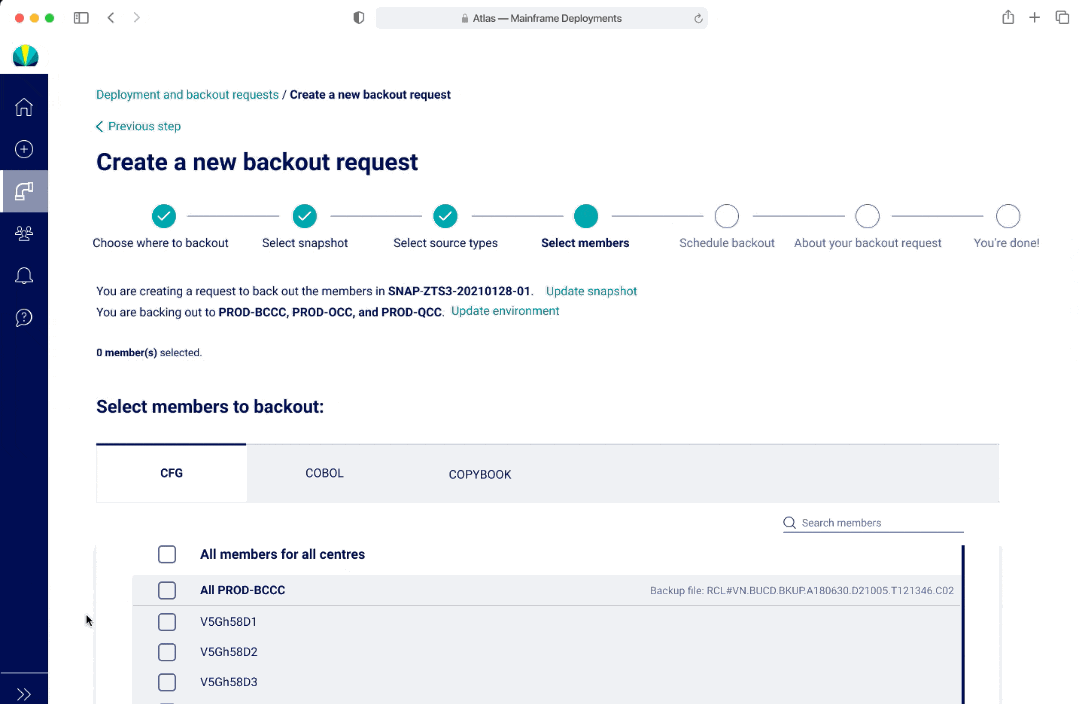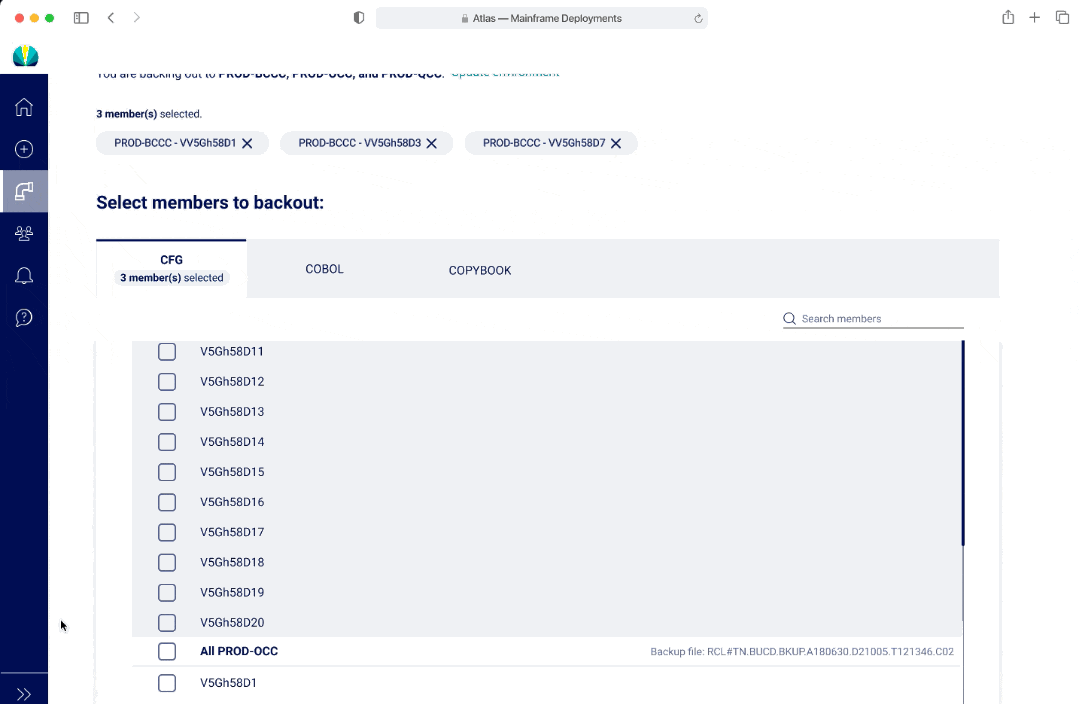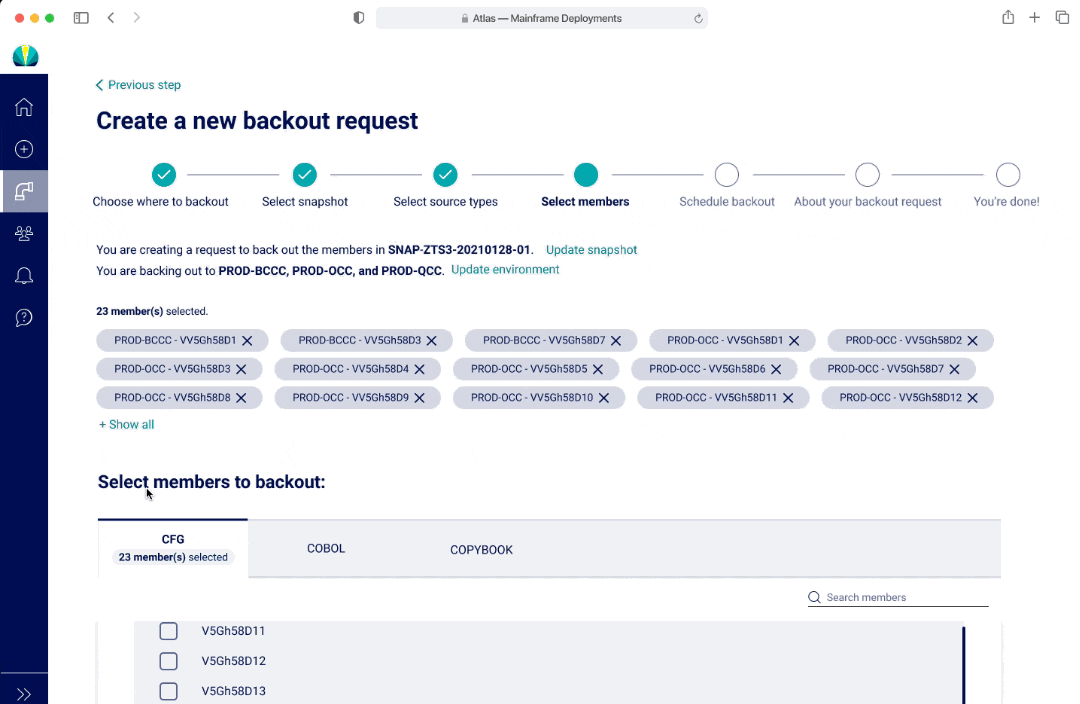
The biggest design challenge with backouts was the concept of selecting source types and members to backout and displaying that visually in the request.
Avg. 15 source types to select from (edge case: could be 3-5, but could go up to 200)
Avg. 50-100 members to select from
Users would typically choose the same members across environments in a source type
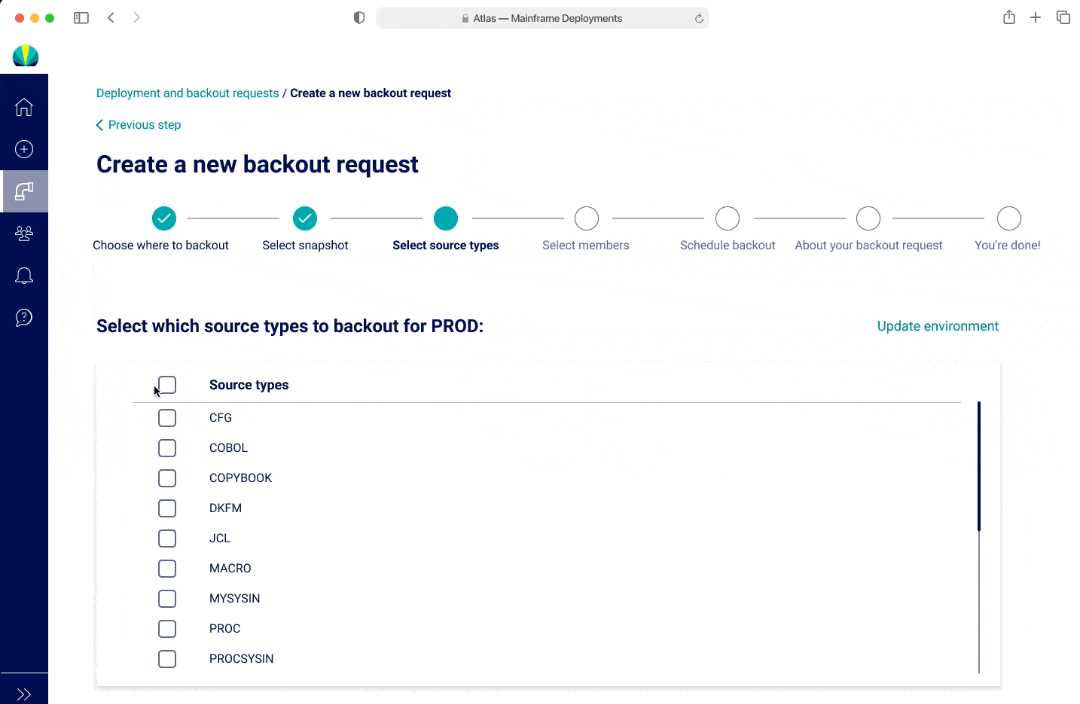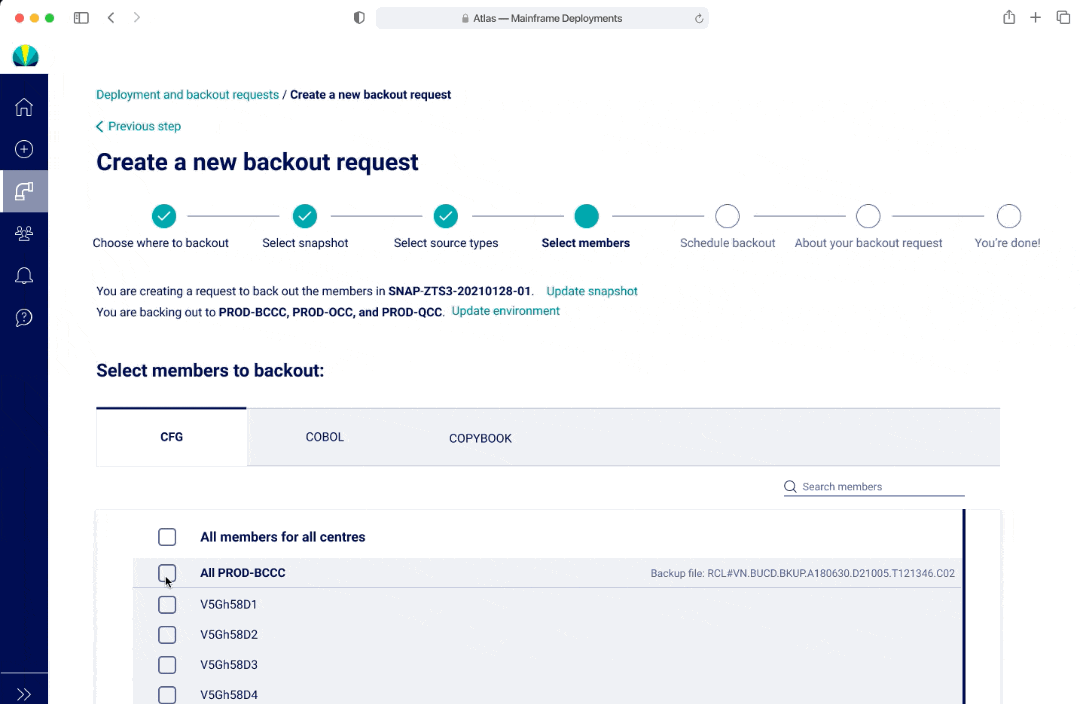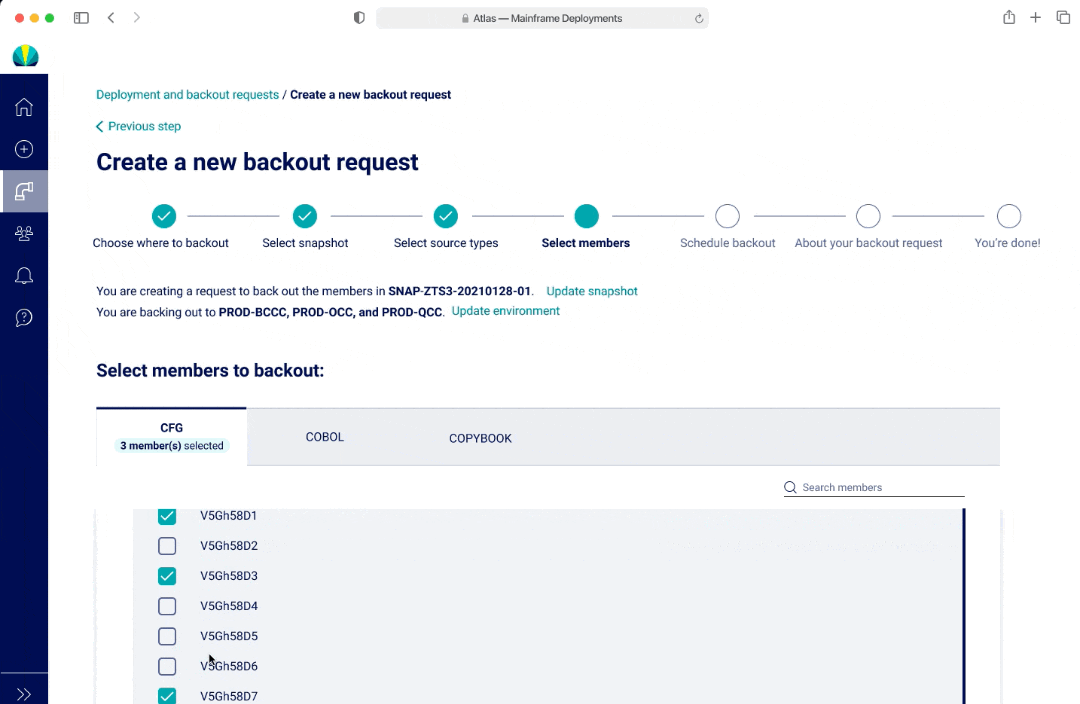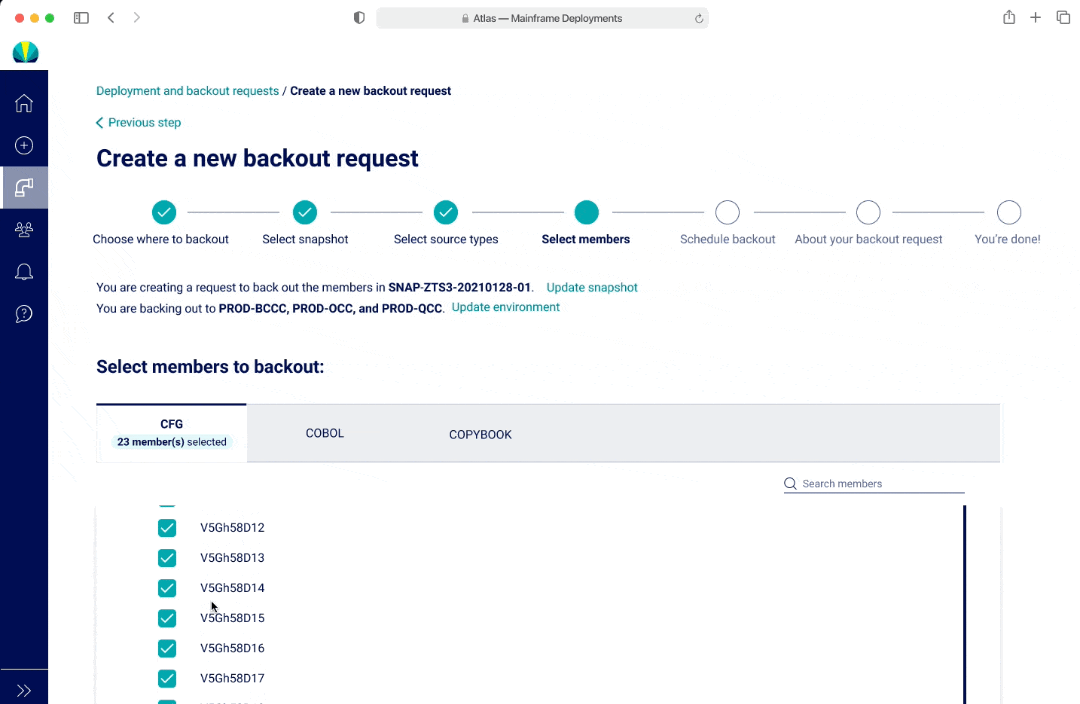
Backouts - V1
Backouts - V2 (Similar to V1 except with pills to show selection)
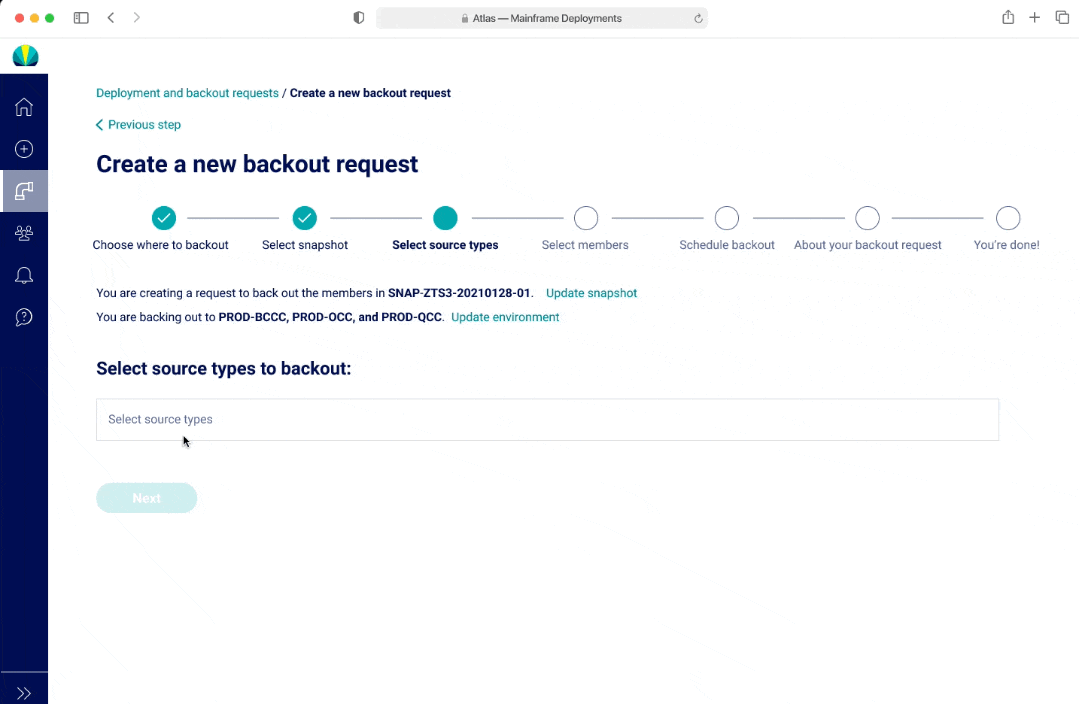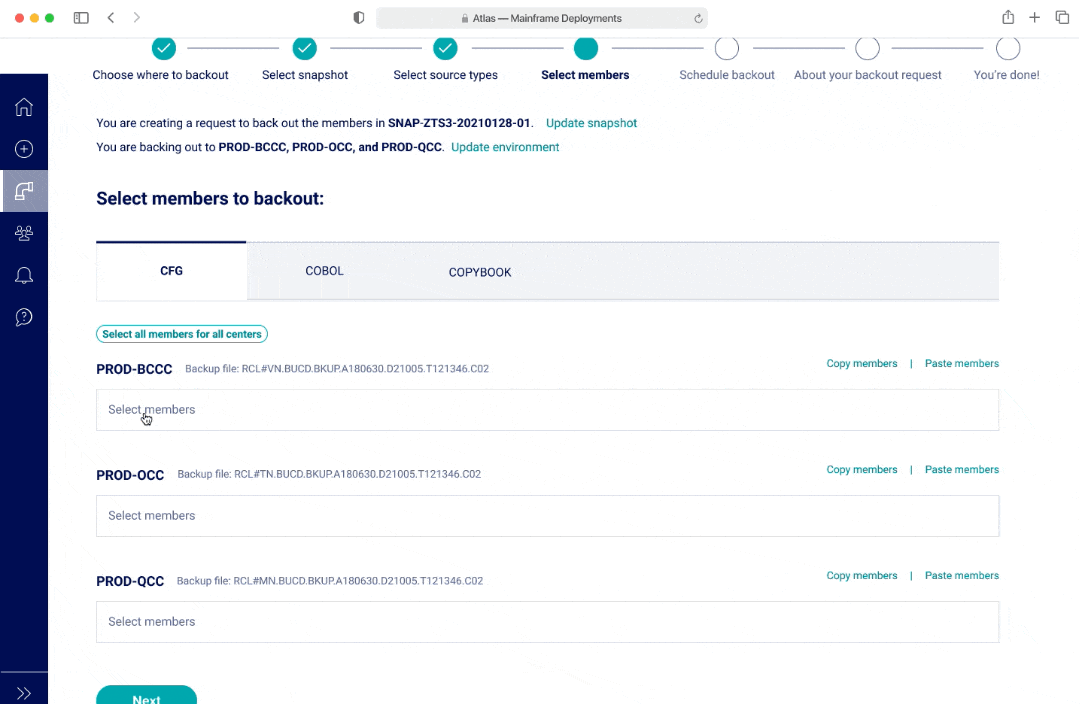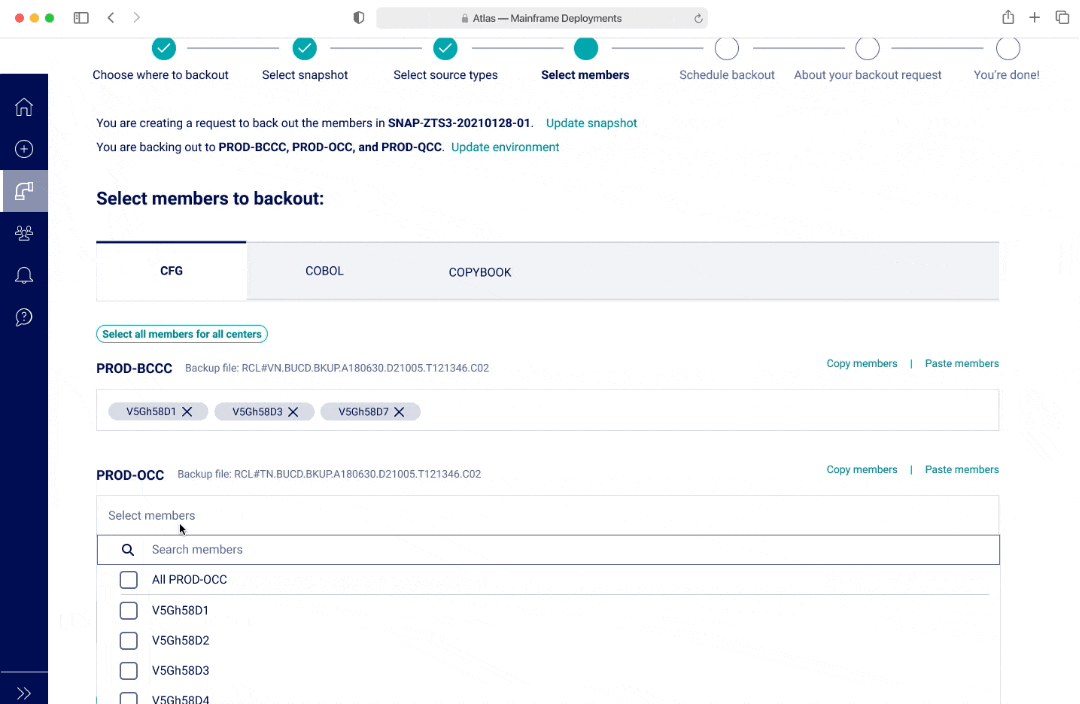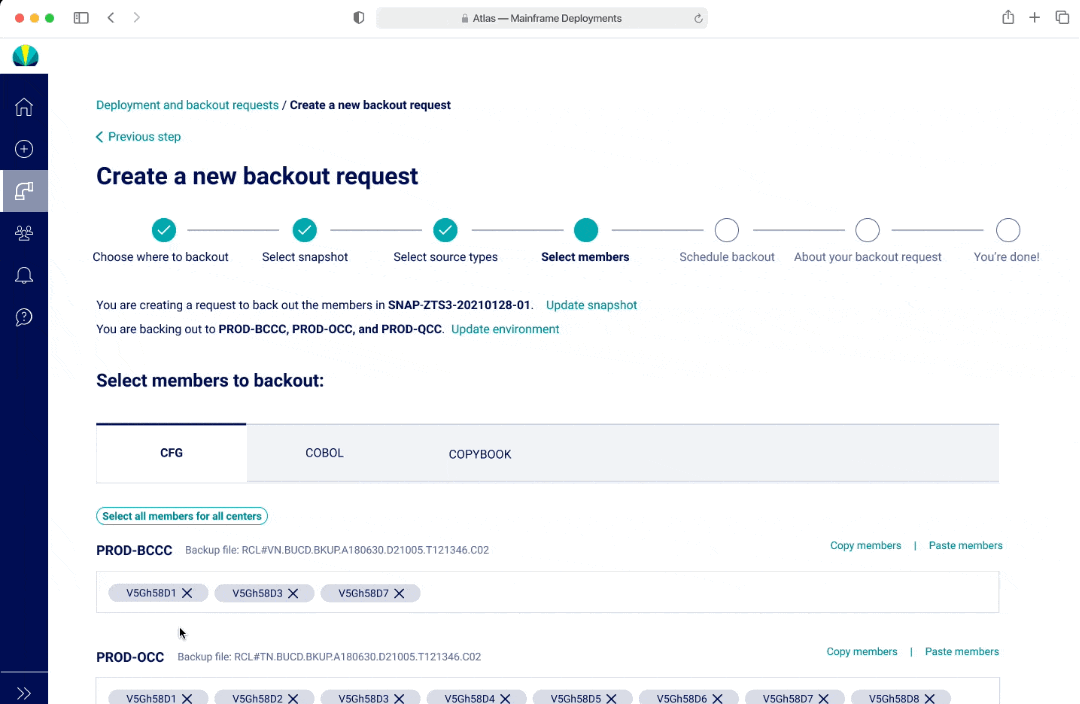
Backouts - V3
In V1 and V2, I had a list to represent both selecting a long list of source types and members. The benefit of having a list was that users would be able to see all options at a glance. In V1, if a user was selecting from a long list, there wasn't a good way to show everything they selected. In V2, the options selected would appear as pills at the top of the page. However this may lead to additional mental load and an interaction where the page and scroll may shift position as the pill selection pushes the list down.
In V3, an user cannot see all the options within a multi-select dropdown at first glance, however there was the ability to separate out the options and streamlined view with seeing all the selections as an user interacts with the dropdown.
Validation and Testing Goals
I first did quick testing using V2/V3 on this specific design problem with 3 users to test the tradeoffs. I had a hypotheses that V2 would lead to more usability errors, however wanted to validate this.
Findings
V2 - 2 users scanned through a list, while 1 user searched for members. The person who searched found it simple, wheras those who scrolled found it frustrating and could not find what they were looking for
V3 - All users liked the grouping by environment when searching by members
V3 - Users took longer to select source types since they had to do it per environment, but expressed less frustration
V3 - The user who searched appreciated the interaction where someone can copy and paste directly to trigger a select
Based on user testing, I decided to use V3 (multi-select dropdowns) as there was less frustration and difficulty in finding source types and members.
Next Steps
One of the exciting things about the mainframe functionality is the ability to onboard 50-60% of applications that have not been able to use Atlas previously. With such an ambiguous initiative, t was rewarding to work with many developers and SMEs to gather feedback and co-design. Due to the short timelines, I worked through quick iteration loops in order to keep momentum and ensure that the designs contained the necessary requirements.
I would have loved to be able to keep a pulse check to gather success metrics. Not only did I want to ensure successful adoption, but that mainframe applications continued to be onboarded and deployed using Atlas (retention) and users would be able to complete these steps successfully.
Looking back, since I had to design for multiple stakeholders in the room, I avoided ambiguity by sticking to a mid-high fidelity but knew that I could have saved time by designing lower fidelity wireframes. I believe I could have done more exploration through quick sketches or wireframes.